

转发一个生产环境中的案例,MySQL 在 Kubernetes IPVS 模式下引发的 TCP 超时问题 - 转发于 https://berlinsaint.github.io/blog/2018/11/01/Mysql_On_Kubernetes%E5%BC%95%E5%8F%91%E7%9A%84TCP%E8%B6%85%E6%97%B6%E9%97%AE%E9%A2%98%E5%AE%9A%E4%BD%8D/
以下数据库上 Kubernetes 都是研发、测试环境,非生产环境
我们研测测试环境的数据库如 Mysql ,redis ,rabbitmq 都以容器的方式在我们自研的 paas 平台上创建;
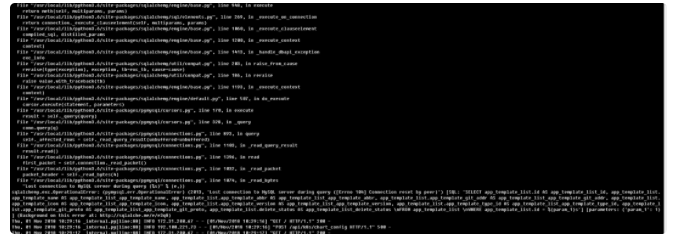
但是当我们把 mysql 移到 k8s 上时, 我们经常发现 MYSQL 的 error 日志爆出如下错误:
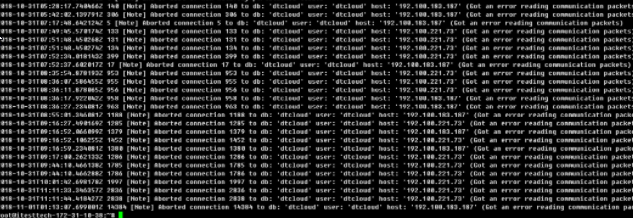
然后我们的客户端则会经常报 Lost Mysql Connection 错误, 重试后,连接恢复:
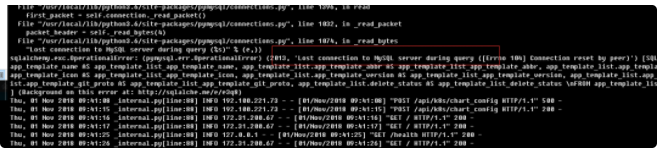
对于该问题,我们首先思路是排查我们代码上是否存在未正常关闭连接, 同时,我们也部署了另一套非容器的 mysql 环境,相同代码下,非容器 mysql 的表现的非常正常,没有一条 Aborted 记录,因此我们怀疑一定中间某个网络环节导致了该问题。
Percona 社区写了一篇比较好的文章,这篇文章有必要阅读下,因为这种错误原因是不确定的。地址是 https://www.percona.com/blog/2016/05/16/mysql-got-an-error-reading-communication-packet-errors/
但是并没有给出这类问题的根本原因,或者说导致该错误的原因其实可能有多种。
由于是基本确立问题范围出现在 docker 网络,所以我们必须要深入了解下 kubernetes 1.11 上的 IPVS 模式原理。
Kubernetes ipvs 基于 LVS-NAT 模型,基本流程如下图:
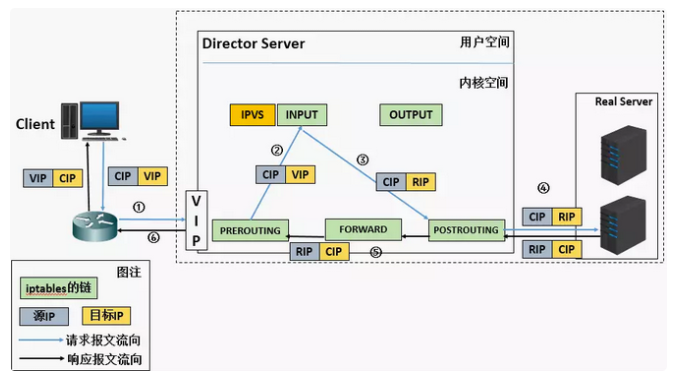
- 当用户请求到达Director Server,此时请求的数据报文会先到达内核的PREROUTING链,此时报文的源IP是CIP,目标IP是VIP(K8S 每个node都会有该VIP子接口,名为kube-ipvs0,为虚拟接口)。
在 Kubernetes 里,这里的 VIP 就是 ClusterIP, 熟悉 kubernetes 的原理可知该 VIP 是 kubernetes Service ,本身就是个负载均衡地址,且各个节点都会监听 VIP 的连接, 当用户请求到达 DS, 这一过程在 k8s 上体现为流量打到 Service 为 VIP 上, DS 是谁呢?每一台 K8S node 都是 DS. 这要看我们是谁去访问 SVC, 在我们的 case 中, Mysql SVC vip 为 10.101.219.112; 访问 Mysql SVC 的是我们的后端 Pod, 我们的 Client Pod 的 PodIP 为 192.100.183.187; 我的 RS POD IP 为 192.100.111.84
- PREROUTING链检查发现数据包的目标IP是本机,将数据包送至INPUT链。
iptables 命令是查不到的 INPUT 这个规则的,因为是 ipvs 的缘故, 使用 ipvsadm -ln 可以查看到如下规则:

- POSTROUTING链通过选路,将数据包发送到Real Server(这个我们不好看到,因为内核态或者有没有好的办法可以告知我。)
- Real Server 比对发现目标IP是自己的 IP,开始建立响应报文发回给 Director Server,此时报文的源 IP 是RIP,目标 IP 是 CIP. 我们这里 CIP 就是
192.100.183.187 - Director Server 在响应客户端之前,此时会将源IP地址修改为自己的IP地址,然后响应给客户端,做SNAT转换。此时报文的源IP是VIP (
10.101.219.112)。目标IP是 CIP。
至此 IPVS原理结束。
回到问题, 我们的问题其实遇到比较长时间了,大概一个背景就是,连续使用问题不大,不会报错,但是搁置一段时间后去访问, 就会出现一些异常(我们web上体现到一些查询查不到数据), 所以我们怀疑网络拓扑中存在着连接超时的问题,究竟哪一块有超时呢?我决定抓包。
在哪抓, 我们客户端是我们一个后端,当它启动时,如果有查询任务,肯定是向mysql 发起请求连接的, 所以我们查到该 Client所在 Node上,宿主机上执行tcpdump;
我们的是calico网络, 需要抓 tunl0网卡流量;
命令如下(幸好第一份工作做网络的。。。。):
$ tcpdump -i tunl0 host 192.100.111.84 -s0 -w client-mysql.pcap
注意不用指定src dst,那样只能抓到单向报文。。
同时我们的 client发起一个mysql查询请求, 并另开一个shell 在该node执行 ipvsadm -lnc
结果如下:


这个图。。。。
第二列 ,很可疑。。。expired date。。。。。超时。。。,先不管,证明我们的猜想。。继续往下走,不断执行该命令, 第二列在减少,看起来默认是15min,那么这15min我client不再做任何查询,等等吧。。。。
waiting。。。

还有5分钟, 好紧张
我们想抓到到15min那时候, 会发生什么, 然后client再去查询,会不会触发 mysql的错误以及client的错误(文初的错误)
时间到:
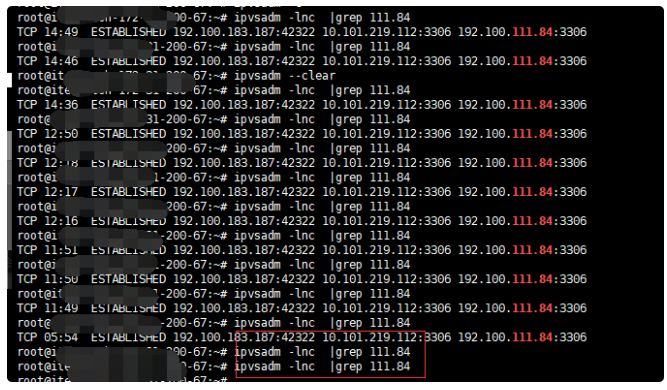
我凑, 看起来该链接被清掉了,这时候我们去执行一条查询看看;
我们再看看抓包情况:(我是在POD所在节点宿主上抓的跟数据库交互的报文,然后没有抓到连接被RST的报文略疑惑,lvs清空连接对连接本身究竟做了什么操作仍需要关注。。)
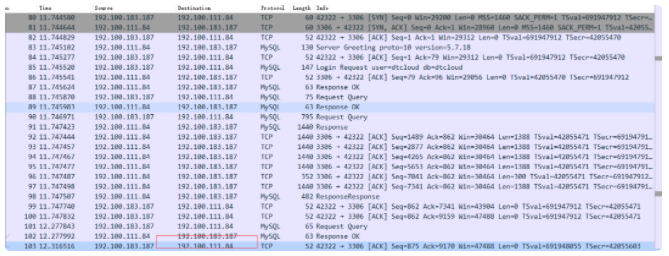
在此之后,查询时候又会新键连接, 即没有任何征兆该链接就被断开了,按理说client使用 mysql connection pool 连接复用是不会轻易就更换连接的。
基本确定了问题, 看起来是 ipvs 维护 VIP的这条链接存在15min左右的超时阈值设定,这个值是否跟系统默认的tcp_keepalive_timeout 有协同影响?那么系统的默认tcp超时时间是多少呢?
确立这个思路,查阅资料(基于15min ipvs为关键词):
https://github.com/moby/moby/issues/31208https://success.docker.com/article/ipvs-connection-timeout-issuehttps://access.redhat.com/solutions/23874
基于上述资料,基本可以分析到, ipvs维护链接有个超时时间,默认为 900s 为 15 分钟;然后操作系统默认的 tcp_keepalive_timeout 默认为 7200s,当一个空闲 tcp 连接达到 900s 时,首先他被ipvs断了,但是操作系统认为该链接还没有到保活超时,所以客户端还会使用之前的连接去发送查询请求,但是ipvs已经不维护该链接了,所以 Lost Connection。。所以只要减小系统的tcp_keepalive_timeout时间,比如到600,后发送一个心跳包,让tcp保活, 这样, ipvs的连接超时也会被重置计数为15min。
我紧急基于上述资料做了 k8s node 全量修改配置:
playbook 如下:
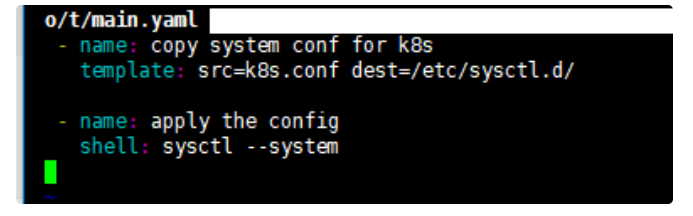
k8s.conf 如下:
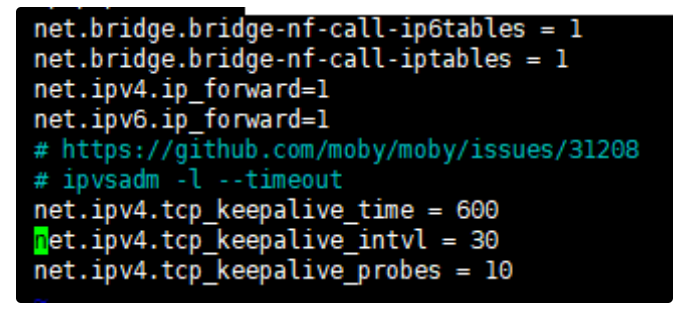
关于这三个参数解释下:
当启用与内核参数或守护程序端配置或客户端配置相关的选项时,它将根据这些选项终止tcp会话。例如,当您将以上述内核参数选项视为示例时,首先将在600秒后开始发送keepalive数据包,之后每隔30秒发送一次下一个数据包10次。当客户端或服务器在这段时间内根本没有应答时,tcp会话将被视为已损坏,并将终止。
- 为什么我们要设置为600s呢, 其实只要比 ipvs的默认值900小即可!
经修复后, 断链问题基本解决, 数据库的 error communication packget 报文基本不再复现, 多么痛的领悟。。
抓到如下报文(修改后ip等数值与上文不一样,发生了变化):
- (可以清楚看到13:33 到 13:43 期间连接无数据,但是10分钟到了,里面有一个KeepAlive报文,修改之前linux 这个值默认是7200s也就是2小时!)
我们可以在 https://access.redhat.com/solutions/23874 看到一些解释
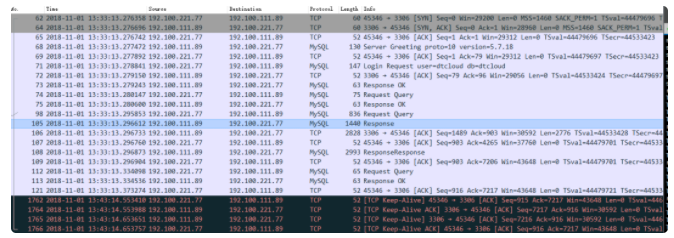
- 该 client 的数据库连接池的连接被保活而不是被 ipvs clear 掉。
评论区