

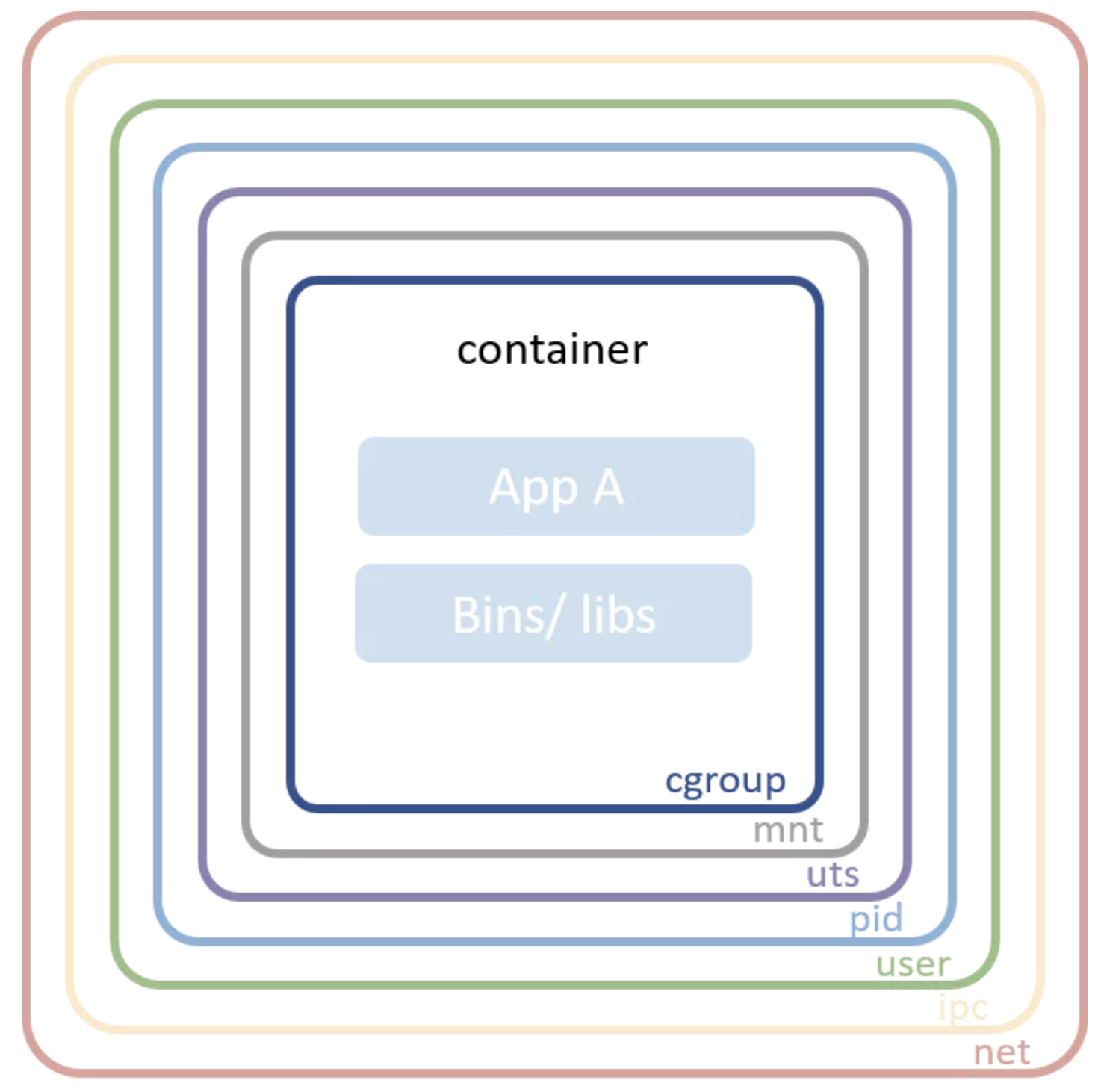
一、Linux 命名空间
Linux 命名空间包含了现代容器中的一些基础技术。从高层来看,这一技术允许把系统资源在进程之间进行隔离。例如 PID 命名空间会会把进程 ID 空间进行隔离,这样同一个主机之中的两个进程就能隔离了。这个级别的隔离对容器世界来说是很重要的。没有命名空间的话,A 容器中的进程可能会卸载 B 容器中的文件系统,或者修改 C 容器的主机名,又或删除 D 容器的网卡。将这些资源纳入命名空间进行管理,A 容器甚至无法感知 B、C、D 容器的存在。
- Mount:隔离文件系统加载点;
- UTS:隔离主机名和域名;
- IPC:隔离跨进程通信(IPC)资源;
- PID:隔离 PID 空间;
- 网络:隔离网络接口;
- 用户:隔离 UID/GID 空间;
- Cgroup:隔离 cgroup 根目录。
绝大多数容器会使用上述命名空间在容器进程之间进行隔离。要注意 cgroup 命名空间出现较晚,相对其它命名空间来说,用的比较少。
二、容器网络(网络命名空间)
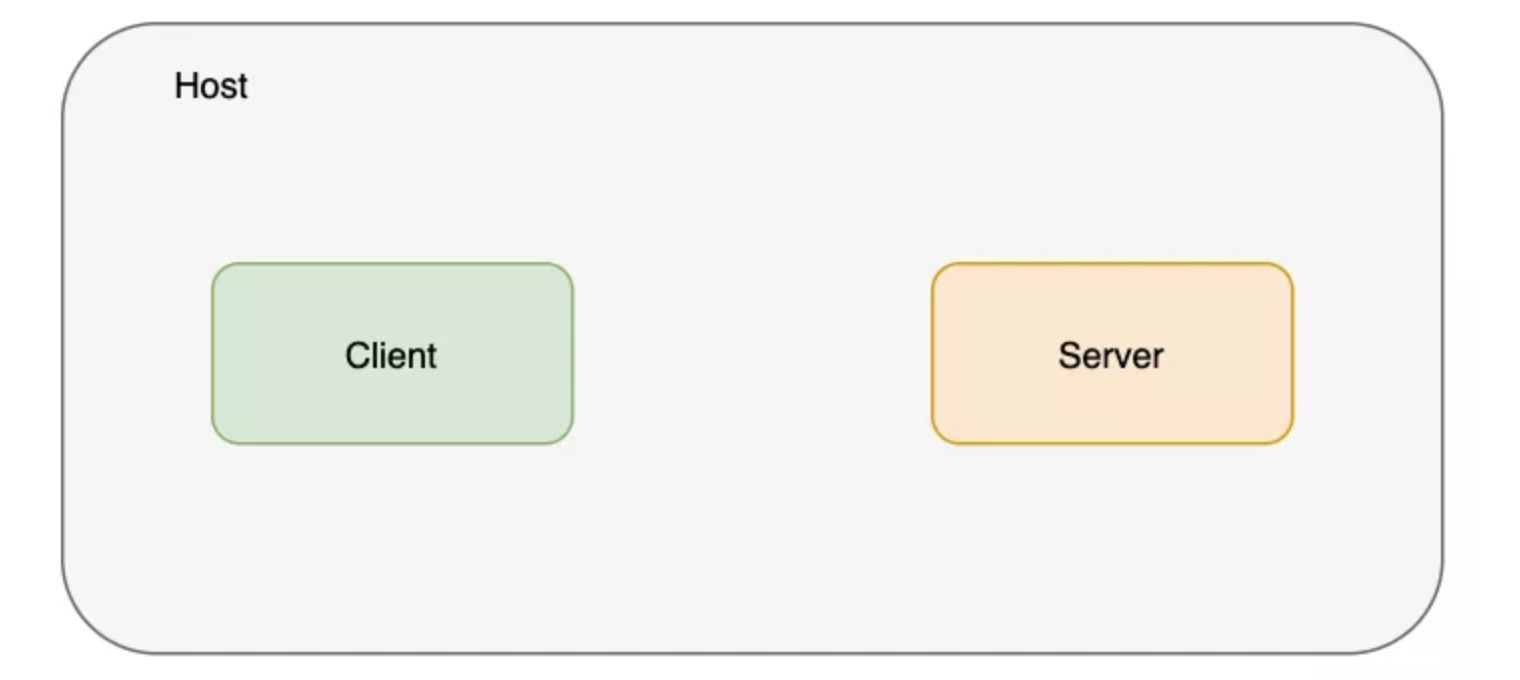
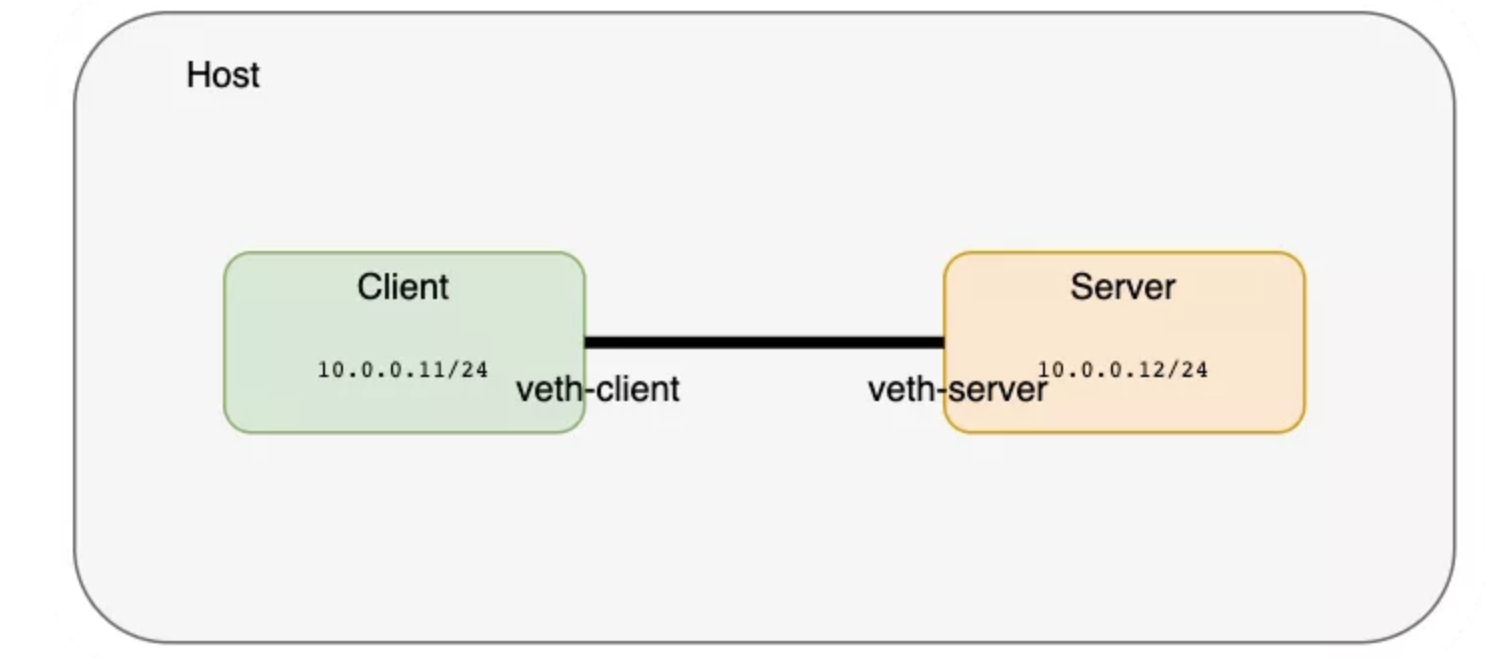
在进入 CNI 和 Docker 之前,首先看看容器网络的核心技术。Linux 内核有不少多租户方面的功能。命名空间对不同种类的资源进行了隔离,网络命名空间隔离的自然就是网络。在主流 Linux 操作系统中都可以简单地用 ip 命令创建网络命名空间。接下来创建两个分别用于服务器和客户端的网络命名空间。
$ ip netns add client
$ ip netns add server
$ ip netns list
server
client
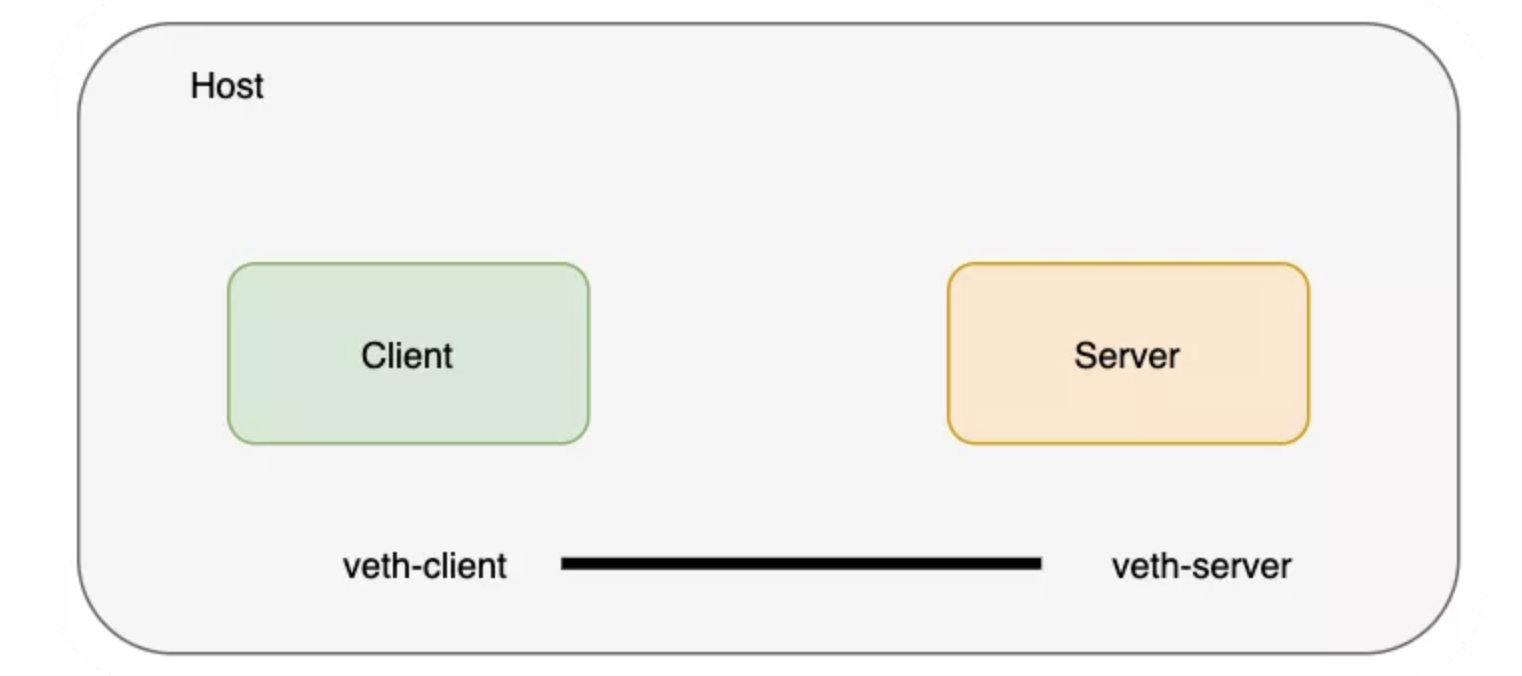
创建一对 veth 将命名空间进行连接,可以把 veth 想象为连接两端的网线。
$ ip link add veth-client type veth peer name veth-server
$ ip link list | grep veth
4: veth-server@veth-client: <BROADCAST,MULTICAST,M-DOWN> mtu 1500 qdisc noop state DOWN mode DEFAULT group default qlen 1000
5: veth-client@veth-server: <BROADCAST,MULTICAST,M-DOWN> mtu 1500 qdisc noop state DOWN mode DEFAULT group default qlen 1000
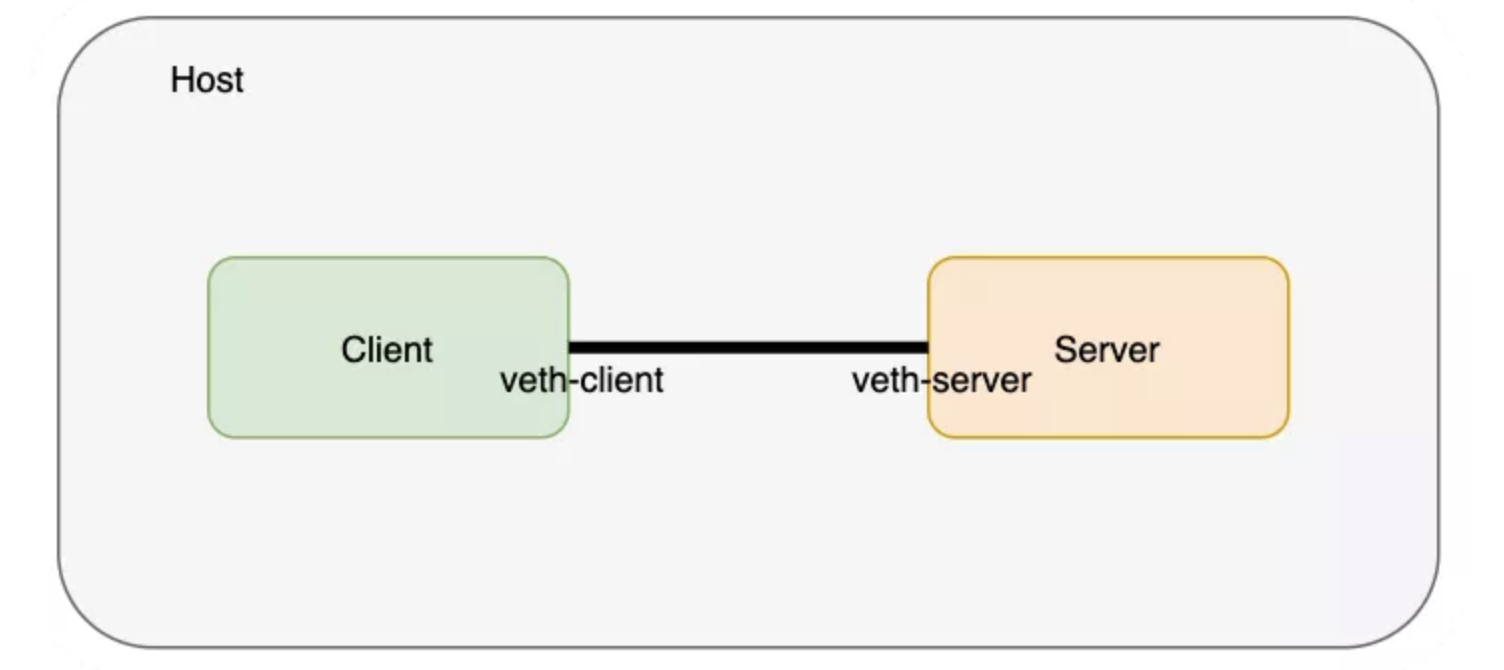
这一对 veth 是存在于主机的网络命名空间的,接下来我们把两端分别置入各自的命名空间:
$ ip link set veth-client netns client
$ ip link set veth-server netns server
$ ip link list | grep veth # doesn’t exist on the host network namespace now
从 client 命名空间检查一下命名空间中的 veth 状况:
$ ip netns exec client ip link
1: lo: <LOOPBACK> mtu 65536 qdisc noop state DOWN mode DEFAULT group default qlen 1 link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
5: veth-client@if4: <BROADCAST,MULTICAST> mtu 1500 qdisc noop state DOWN mode DEFAULT group default qlen 1000 link/ether ca:e8:30:2e:f9:d2 brd ff:ff:ff:ff:ff:ff link-netnsid 1
然后是 server 命名空间:
$ ip netns exec server ip link
1: lo: <LOOPBACK> mtu 65536 qdisc noop state DOWN mode DEFAULT group default qlen 1 link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
4: veth-server@if5: <BROADCAST,MULTICAST> mtu 1500 qdisc noop state DOWN mode DEFAULT group default qlen 1000 link/ether 42:96:f0:ae:f0:c5 brd ff:ff:ff:ff:ff:ff link-netnsid 0
接下来给这些网络接口分配 IP 地址并启用:
$ ip netns exec client ip address add 10.0.0.11/24 dev veth-client
$ ip netns exec client ip link set veth-client up
$ ip netns exec server ip address add 10.0.0.12/24 dev veth-server
$ ip netns exec server ip link set veth-server up
$
$ ip netns exec client ip addr
1: lo: <LOOPBACK> mtu 65536 qdisc noop state DOWN group default qlen 1
link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
5: veth-client@if4: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc noqueue state UP group default qlen 1000
link/ether ca:e8:30:2e:f9:d2 brd ff:ff:ff:ff:ff:ff link-netnsid 1
inet 10.0.0.11/24 scope global veth-client
valid_lft forever preferred_lft forever
inet6 fe80::c8e8:30ff:fe2e:f9d2/64 scope link
valid_lft forever preferred_lft forever
$
$ ip netns exec server ip addr
1: lo: <LOOPBACK> mtu 65536 qdisc noop state DOWN group default qlen 1
link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
4: veth-server@if5: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc noqueue state UP group default qlen 1000
link/ether 42:96:f0:ae:f0:c5 brd ff:ff:ff:ff:ff:ff link-netnsid 0
inet 10.0.0.12/24 scope global veth-server
valid_lft forever preferred_lft forever
inet6 fe80::4096:f0ff:feae:f0c5/64 scope link
valid_lft forever preferred_lft forever
在 client 命名空间中使用 ping 命令检查一下两个网络命名空间的连接状况:
$ ip netns exec client ping 10.0.0.12
PING 10.0.0.12 (10.0.0.12) 56(84) bytes of data.
64 bytes from 10.0.0.12: icmp_seq=1 ttl=64 time=0.101 ms
64 bytes from 10.0.0.12: icmp_seq=2 ttl=64 time=0.072 ms
64 bytes from 10.0.0.12: icmp_seq=3 ttl=64 time=0.084 ms
64 bytes from 10.0.0.12: icmp_seq=4 ttl=64 time=0.077 ms
64 bytes from 10.0.0.12: icmp_seq=5 ttl=64 time=0.079 ms
如果要创建更网络命名空间并互相连接,用 veth 对将这些网络命名空间进行两两连接就很麻烦了。可以创建创建一个 Linux 网桥来连接这些网络命名空间。Docker 就是这样为同一主机内的容器进行连接的。下面就创建网络命名空间并用网桥连接起来:
# All in one
# ip link add <p1-name> netns <p1-ns> type veth peer <p2-name> netns <p2-ns>
BR=bridge1
HOST_IP=172.17.0.33
# 新创建一对类型为veth peer的网卡
ip link add client1-veth type veth peer name client1-veth-br
ip link add server1-veth type veth peer name server1-veth-br
ip link add $BR type bridge
ip netns add client1
ip netns add server1
ip link set client1-veth netns client1
ip link set server1-veth netns server1
ip link set client1-veth-br master $BR
ip link set server1-veth-br master $BR
ip link set $BR up
ip link set client1-veth-br up
ip link set server1-veth-br up
ip netns exec client1 ip link set client1-veth up
ip netns exec server1 ip link set server1-veth up
ip netns exec client1 ip addr add 172.30.0.11/24 dev client1-veth
ip netns exec server1 ip addr add 172.30.0.12/24 dev server1-veth
ip netns exec client1 ping 172.30.0.12 -c 5
ip addr add 172.30.0.1/24 dev $BR
ip netns exec client1 ping 172.30.0.12 -c 5
ip netns exec client1 ping 172.30.0.1 -c 5
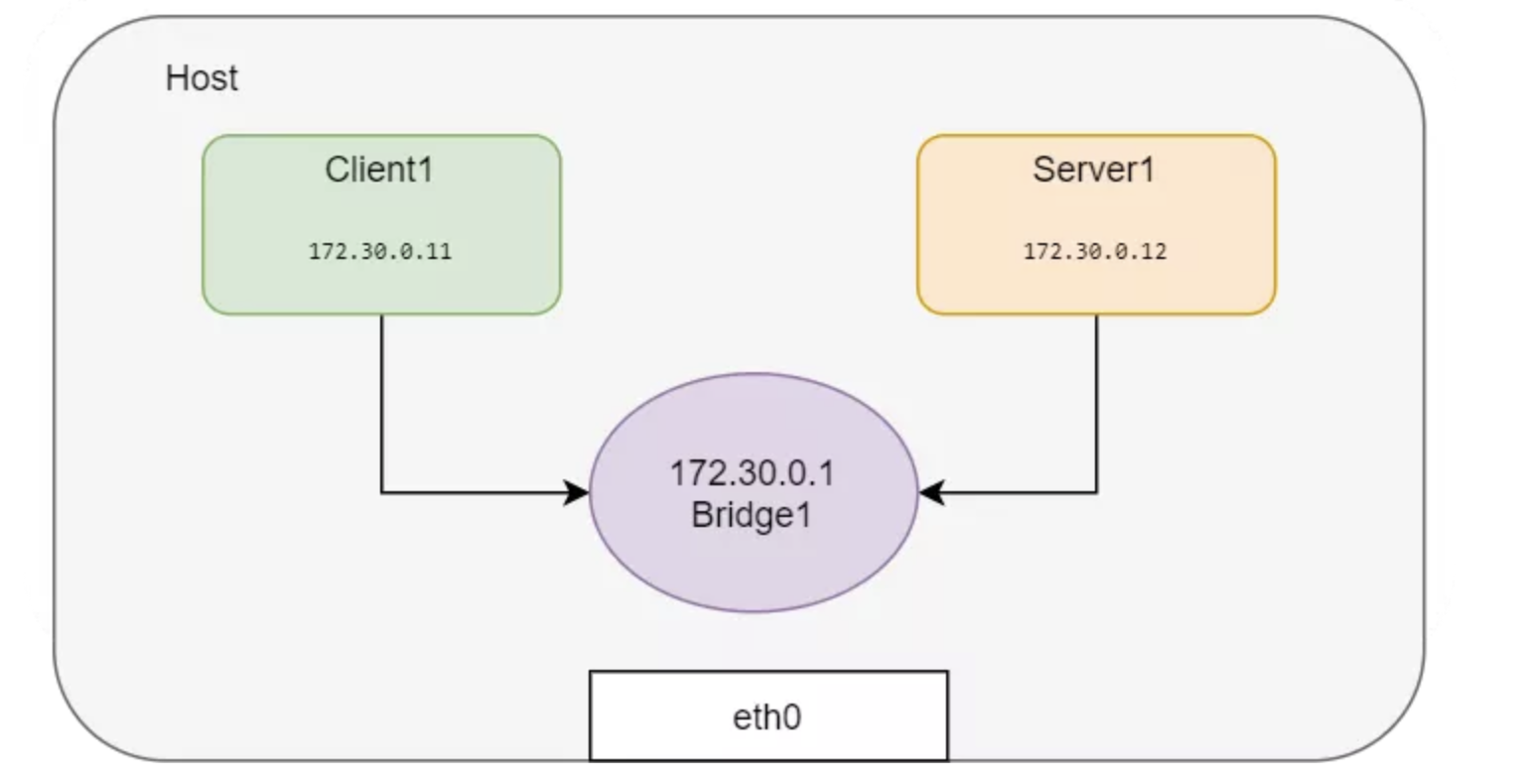
还是用 ping 命令检查两个网络命名空间的连接性:
$ ip netns exec client1 ping 172.30.0.12 -c 5
PING 172.30.0.12 (172.30.0.12) 56(84) bytes of data.
64 bytes from 172.30.0.12: icmp_seq=1 ttl=64 time=0.138 ms
64 bytes from 172.30.0.12: icmp_seq=2 ttl=64 time=0.091 ms
64 bytes from 172.30.0.12: icmp_seq=3 ttl=64 time=0.073 ms
64 bytes from 172.30.0.12: icmp_seq=4 ttl=64 time=0.070 ms
64 bytes from 172.30.0.12: icmp_seq=5 ttl=64 time=0.107 ms
从命名空间中 ping 一下主机 IP:
$ ip netns exec client1 ping $HOST_IP -c 2
connect: Network is unreachable
Network is unreachable 的原因是路由不通,加入一条缺省路由:
$ ip netns exec client1 ip route add default via 172.30.0.1
$ ip netns exec server1 ip route add default via 172.30.0.1
$ ip netns exec client1 ping $HOST_IP -c 5
PING 172.17.0.23 (172.17.0.23) 56(84) bytes of data.
64 bytes from 172.17.0.23: icmp_seq=1 ttl=64 time=0.053 ms
64 bytes from 172.17.0.23: icmp_seq=2 ttl=64 time=0.121 ms
64 bytes from 172.17.0.23: icmp_seq=3 ttl=64 time=0.078 ms
64 bytes from 172.17.0.23: icmp_seq=4 ttl=64 time=0.129 ms
64 bytes from 172.17.0.23: icmp_seq=5 ttl=64 time=0.119 ms
--- 172.17.0.23 ping statistics ---
5 packets transmitted, 5 received, 0% packet loss, time 3999ms
rtt min/avg/max/mdev = 0.053/0.100/0.129/0.029 ms
default 路由打通了网桥的通信,这样这个命名空间就能和外部网络进行通信了:
$ ping 8.8.8.8 -c 2
PING 8.8.8.8 (8.8.8.8) 56(84) bytes of data.
64 bytes from 8.8.8.8: icmp_seq=1 ttl=117 time=3.40 ms
64 bytes from 8.8.8.8: icmp_seq=2 ttl=117 time=3.81 ms
--- 8.8.8.8 ping statistics ---
2 packets transmitted, 2 received, 0% packet loss, time 1001ms
rtt min/avg/max/mdev = 3.403/3.610/3.817/0.207 ms
三、从外部服务器连接内网
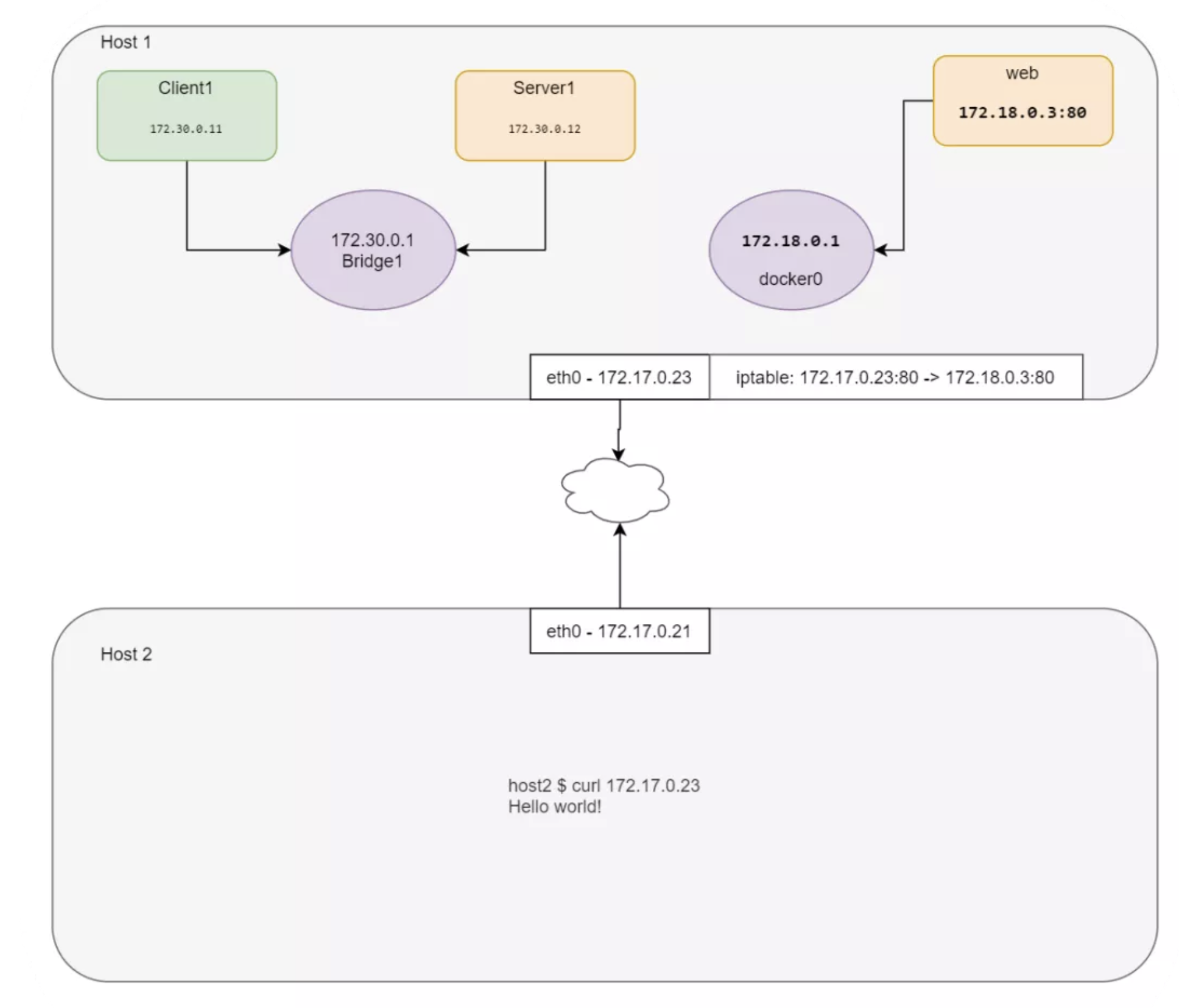
如你所见,这里演示用的机器已经安装了 Docker,也就是说已经创建了 docker0 网桥。测试场景需要所有网络命名空间的协同,进行 Web Server 的测试有些复杂,因此这里就借用一下 docker0:
docker0 Link encap:Ethernet HWaddr 02:42:e2:44:07:39
inet addr:172.18.0.1 Bcast:172.18.0.255 Mask:255.255.255.0
UP BROADCAST MULTICAST MTU:1500 Metric:1
RX packets:0 errors:0 dropped:0 overruns:0 frame:0
TX packets:0 errors:0 dropped:0 overruns:0 carrier:0
collisions:0 txqueuelen:0
RX bytes:0 (0.0 B) TX bytes:0 (0.0 B)
运行一个 nginx 容器并进行观察:
$ docker run -d --name web --rm nginx
efff2d2c98f94671f69cddc5cc88bb7a0a5a2ea15dc3c98d911e39bf2764a556
$ WEB_IP=`docker inspect -f "{{ .NetworkSettings.IPAddress }}" web`
$ docker inspect web --format '{{ .NetworkSettings.SandboxKey }}'
/var/run/docker/netns/c009f2a4be71
Docker 创建的 netns 没有保存在缺省位置,所以 ip netns list 是看不到这个网络命名空间的。我们可以在缺省位置创建一个符号链接:
$ container_id=web
$ container_netns=$(docker inspect ${container_id} --format '{{ .NetworkSettings.SandboxKey }}')
$ mkdir -p /var/run/netns
$ rm -f /var/run/netns/${container_id}
$ ln -sv ${container_netns} /var/run/netns/${container_id}
'/var/run/netns/web' -> '/var/run/docker/netns/c009f2a4be71'
$ ip netns list
web (id: 3)
server1 (id: 1)
client1 (id: 0)
看看 web 命名空间的 IP 地址:
$ ip netns exec web ip addr
1: lo: <LOOPBACK,UP,LOWER_UP> mtu 65536 qdisc noqueue state UNKNOWN group default qlen 1
link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
inet 127.0.0.1/8 scope host lo
valid_lft forever preferred_lft forever
11: eth0@if12: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc noqueue state UP group default
link/ether 02:42:ac:12:00:03 brd ff:ff:ff:ff:ff:ff link-netnsid 0
inet 172.18.0.3/24 brd 172.18.0.255 scope global eth0
valid_lft forever preferred_lft forever
然后看看容器里的 IP 地址:
$ WEB_IP=`docker inspect -f "{{ .NetworkSettings.IPAddress }}" web`
$ echo $WEB_IP
172.18.0.3
从主机访问一下 web 命名空间的服务:
$ curl $WEB_IP
<!DOCTYPE html>
<html>
<head>
<title>Welcome to nginx!</title>
...
加入端口转发规则,其它主机就能访问这个 nginx 了:
$ iptables -t nat -A PREROUTING -p tcp --dport 80 -j DNAT --to-destination $WEB_IP:80
$ echo $HOST_IP
172.17.0.23
使用主机 IP 访问 Nginx:
$ curl 172.17.0.23
<!DOCTYPE html>
<html>
<head>
<title>Welcome to nginx!</title>
<style>
body {
width: 35em;
margin: 0 auto;
font-family: Tahoma, Verdana, Arial, sans-serif;
}
</style>
</head>
<body>
<h1>Welcome to nginx!</h1>
<p>If you see this page, the nginx web server is successfully installed and
working. Further configuration is required.</p>
<p>For online documentation and support please refer to
<a href="http://nginx.org/">nginx.org</a>.<br/>
Commercial support is available at
<a href="http://nginx.com/">nginx.com</a>.</p>
<p><em>Thank you for using nginx.</em></p>
</body>
</html>
CNI 插件会执行上面的过程(不完全相同,但是类似)来设置 loopback、eth0,并给容器分配 IP。容器运行时调用 CNI 设置 Pod 网络,接下来讨论一下 CNI。
四、CNI 是什么
CNI 插件负责在容器网络命名空间中插入一个网络接口(也就是
veth对中的一端)并在主机侧进行必要的变更(把veth对中的另一侧接入网桥)。然后给网络接口分配 IP,并调用 IPAM 插件来设置相应的路由。
看起来很眼熟吧?是的,我们在前面的容器网络部分已经说了这些内容。CNI 是一个 CNCF 项目,其中包含了在 Linux 容器进行网络配置的规范和库。CNI 的主要工作就是容器网络的连接能力,并在容器销毁时移除相应的已分配资源。这种专注性使得 CNI 易于实现,因此被广泛接受。
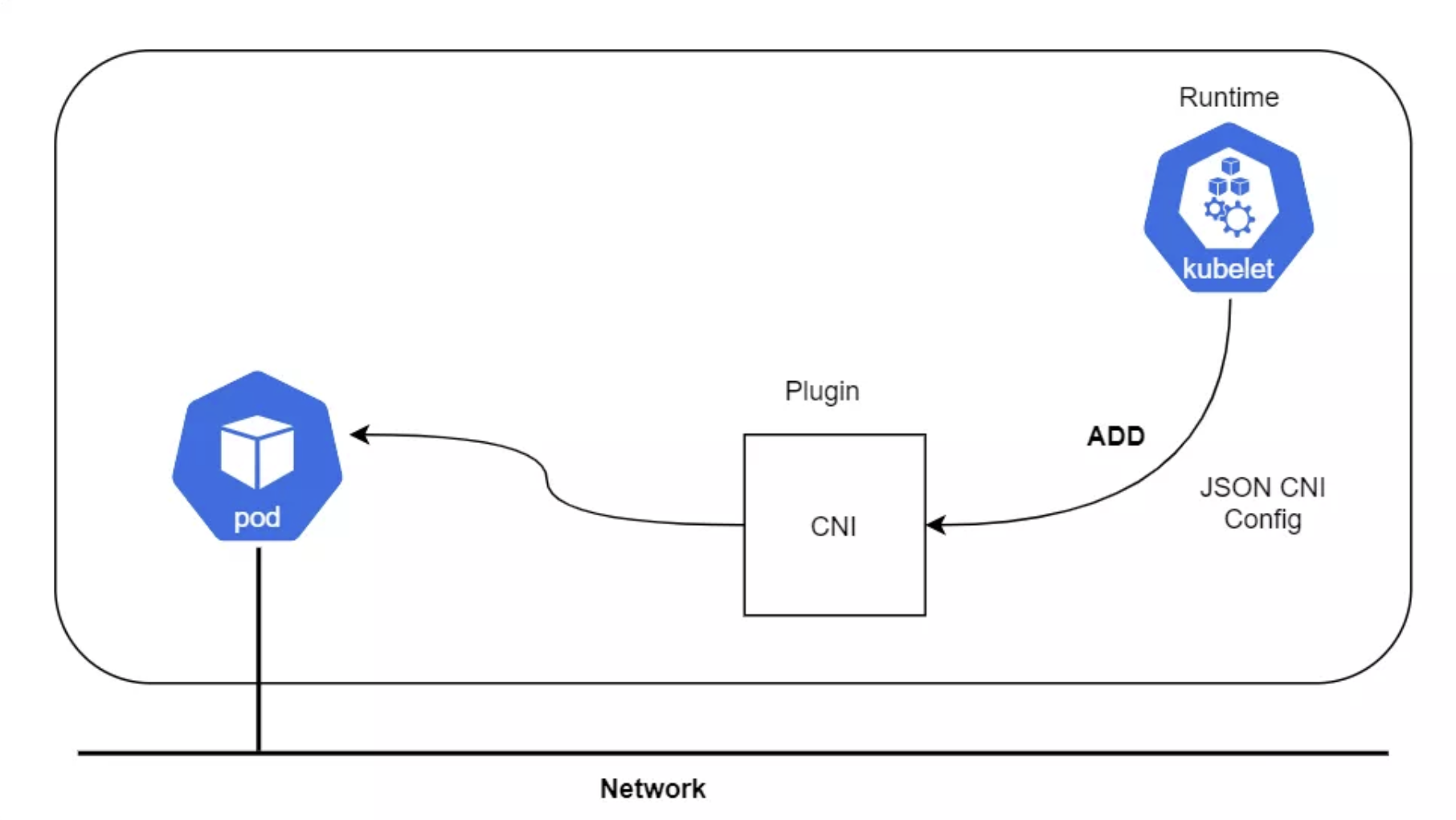
此处所说的运行时可能是 Kubernetes、Podman 、cloud Foundry等等。
CNI 规范
https://github.com/containernetworking/cni/blob/master/SPEC.md
在我首次阅读时,注意到了一些点:
- 因为 Docker 等运行时会为每个容器新建一个网络命名空间,所以规范把容器定义为 Linux 网络命名空间;
- CNI 的网络定义用 JSON 格式存储;
- 网络定义通过 STDIN 发送给插件;换句话说主机上并没有网络配置文件;
- 其他参数通过环境变量进行传递;
- CNI 插件是可执行文件;
- CNI 插件负责容器的网络;换句话说,它需要完成所有容器接入网络所需的工作。在 Docker 中会包含把容器网络命名空间连回主机的工作;
- CNI 插件负责 IPAM 工作,其中包括 IP 地址分配和路由设置。
接下来尝试脱离 Kubernetes 模拟创建 Pod,并使用 CNI 插件而非 CLI 命令进行 IP 分配。完成 Demo 就会更好地理解 Kubernetes 中 Pod 的本质。
第一步:下载 CNI 插件:
$ mkdir cni
$ cd cni
$ curl -O -L https://github.com/containernetworking/cni/releases/download/v0.4.0/cni-amd64-v0.4.0.tgz
% Total % Received % Xferd Average Speed Time Time Time Current
Dload Upload Total Spent Left Speed
100 644 100 644 0 0 1934 0 --:--:-- --:--:-- --:--:-- 1933
100 15.3M 100 15.3M 0 0 233k 0 0:01:07 0:01:07 --:--:-- 104k
$ tar -xvf cni-amd64-v0.4.0.tgz
./
./macvlan
./dhcp
./loopback
./ptp
./ipvlan
./bridge
./tuning
./noop
./host-local
./cnitool
./flannel
第二步,创建一个 JSON 格式的 CNI 配置(00-demo.conf):
{
"cniVersion": "0.2.0",
"name": "demo_br",
"type": "bridge",
"bridge": "cni_net0",
"isGateway": true,
"ipMasq": true,
"ipam": {
"type": "host-local",
"subnet": "10.0.10.0/24",
"routes": [
{ "dst": "0.0.0.0/0" },
{ "dst": "1.1.1.1/32", "gw":"10.0.10.1"}
]
}
}
CNI 配置参数:
-:CNI generic parameters:-
cniVersion: The version of the CNI spec in which the definition works with
name: The network name
type: The name of the plugin you wish to use. In this case, the actual name of the plugin executable
args: Optional additional parameters
ipMasq: Configure outbound masquerade (source NAT) for this network
ipam:
type: The name of the IPAM plugin executable
subnet: The subnet to allocate out of (this is actually part of the IPAM plugin)
routes:
dst: The subnet you wish to reach
gw: The IP address of the next hop to reach the dst. If not specified the default gateway for the subnet is assumed
dns:
nameservers: A list of nameservers you wish to use with this network
domain: The search domain to use for DNS requests
search: A list of search domains
options: A list of options to be passed to the receiver
第三步:创建一个网络为 none 的容器,这个容器没有网络地址。可以用任意的镜像创建该容器,这里我用 pause 来模拟 Kubernetes:
$ docker run --name pause_demo -d --rm --network none kubernetes/pause
Unable to find image 'kubernetes/pause:latest' locally
latest: Pulling from kubernetes/pause
4f4fb700ef54: Pull complete
b9c8ec465f6b: Pull complete
Digest: sha256:b31bfb4d0213f254d361e0079deaaebefa4f82ba7aa76ef82e90b4935ad5b105
Status: Downloaded newer image for kubernetes/pause:latest
763d3ef7d3e943907a1f01f01e13c7cb6c389b1a16857141e7eac0ac10a6fe82
$ container_id=pause_demo
$ container_netns=$(docker inspect ${container_id} --format '{{ .NetworkSettings.SandboxKey }}')
$ mkdir -p /var/run/netns
$ rm -f /var/run/netns/${container_id}
$ ln -sv ${container_netns} /var/run/netns/${container_id}
'/var/run/netns/pause_demo' -> '/var/run/docker/netns/0297681f79b5'
$ ip netns list
pause_demo
$ ip netns exec $container_id ifconfig
lo Link encap:Local Loopback
inet addr:127.0.0.1 Mask:255.0.0.0
UP LOOPBACK RUNNING MTU:65536 Metric:1
RX packets:0 errors:0 dropped:0 overruns:0 frame:0
TX packets:0 errors:0 dropped:0 overruns:0 carrier:0
collisions:0 txqueuelen:1
RX bytes:0 (0.0 B) TX bytes:0 (0.0 B)
第四步:用前面的配置来调用 CNI 插件:
$ CNI_CONTAINERID=$container_id CNI_IFNAME=eth10 CNI_COMMAND=ADD CNI_NETNS=/var/run/netns/$container_id CNI_PATH=`pwd` ./bridge </tmp/00-demo.conf
2020/10/17 17:32:37 Error retriving last reserved ip: Failed to retrieve last reserved ip: open /var/lib/cni/networks/demo_br/last_reserved_ip: no such file or directory
{
"ip4": {
"ip": "10.0.10.2/24",
"gateway": "10.0.10.1",
"routes": [
{
"dst": "0.0.0.0/0"
},
{
"dst": "1.1.1.1/32",
"gw": "10.0.10.1"
}
]
},
"dns": {}
CNI_COMMAND=ADD:
动作,可选范围包括 ADD、DEL 和 CHECK;
CNI_CONTAINER=pause_demo:
通知 CNI 对 pause_demo 网络命名空间进行操作;
CNI_NETNS=/var/run/netns/pause_demo:
命名空间所在路径;
CNI_IFNAME=eth10:
在容器端创建的网络接口名称;
CNI_PATH=pwd:
CNI 插件的可执行文件的位置,在本例中我们的当前目录已经是 cni 目录,因此这个环境变量设置为 pwd即可.
强烈建议阅读 CNI 规范以获知更多 CNI 插件及其功能的信息。在同一个 JSON 文件中可以使用多个插件形成调用链,可以用于建立防火墙规则等类似操作。
第五步,运行上面的命令会返回一些内容。
首先是因为 IPAM 驱动在本地找不到保存 IP 信息的文件而报错。但是因为第一次运行插件时会创建这个文件,所以在其他命名空间再次运行这个命令就不会出现这个问题了。
其次是得到一个说明插件已经完成相应 IP 配置的 JSON 信息。在本例中,网桥的 IP 地址应该是 10.0.10.1/24,命名空间网络接口的地址则是 10.0.10.2/24。另外还会根据我们的 JSON 配置文件,加入缺省路由以及 1.1.1.1/32 路由。检查一下:
$ ip netns exec pause_demo ifconfig
eth10 Link encap:Ethernet HWaddr 0a:58:0a:00:0a:02
inet addr:10.0.10.2 Bcast:0.0.0.0 Mask:255.255.255.0
UP BROADCAST RUNNING MULTICAST MTU:1500 Metric:1
RX packets:18 errors:0 dropped:0 overruns:0 frame:0
TX packets:0 errors:0 dropped:0 overruns:0 carrier:0
collisions:0 txqueuelen:0
RX bytes:1476 (1.4 KB) TX bytes:0 (0.0 B)
lo Link encap:Local Loopback
inet addr:127.0.0.1 Mask:255.0.0.0
UP LOOPBACK RUNNING MTU:65536 Metric:1
RX packets:0 errors:0 dropped:0 overruns:0 frame:0
TX packets:0 errors:0 dropped:0 overruns:0 carrier:0
collisions:0 txqueuelen:1
RX bytes:0 (0.0 B) TX bytes:0 (0.0 B)
$ ip netns exec pause_demo ip route
default via 10.0.10.1 dev eth10
1.1.1.1 via 10.0.10.1 dev eth10
10.0.10.0/24 dev eth10 proto kernel scope link src 10.0.10.2
CNI 创建了网桥并根据 JSON 信息进行了相应配置:
$ ifconfig
cni_net0 Link encap:Ethernet HWaddr 0a:58:0a:00:0a:01
inet addr:10.0.10.1 Bcast:0.0.0.0 Mask:255.255.255.0
inet6 addr: fe80::c4a4:2dff:fe4b:aa1b/64 Scope:Link
UP BROADCAST RUNNING MULTICAST MTU:1500 Metric:1
RX packets:7 errors:0 dropped:0 overruns:0 frame:0
TX packets:20 errors:0 dropped:0 overruns:0 carrier:0
collisions:0 txqueuelen:1000
RX bytes:1174 (1.1 KB) TX bytes:1545 (1.5 KB)
第六步,启动 Web Server 并共享 pause 容器命名空间:
$ docker run --name web_demo -d --rm --network container:$container_id nginx8fadcf2925b779de6781b4215534b32231685b8515f998b2a66a3c7e38333e30
第七步,使用 pause 容器的 IP 地址访问 Web Server:
$ curl `cat /var/lib/cni/networks/demo_br/last_reserved_ip`
<!DOCTYPE html>
<html>
<head>
<title>Welcome to ngi,nx!</title>
<style>
body {
width: 35em;
margin: 0 auto;
font-family: Tahoma, Verdana, Arial, sans-serif;
}
</style>
</head>
...
五、Pod 网络命名空间
接触 Kubernetes 最应该知道的一个问题就是,Pod 不等于容器,而是一组容器。这一组容器会共享同一个网络栈。每个 Pod 都会包含有 pause 容器,Kubernetes 通过这个容器来管理 Pod 的网络。所有其他容器都会附着在 pause 容器的网络命名空间中,而 pause 除了网络之外,再无其他作用。因此同一个 Pod 中的不同容器,可以通过 localhost 进行互访:
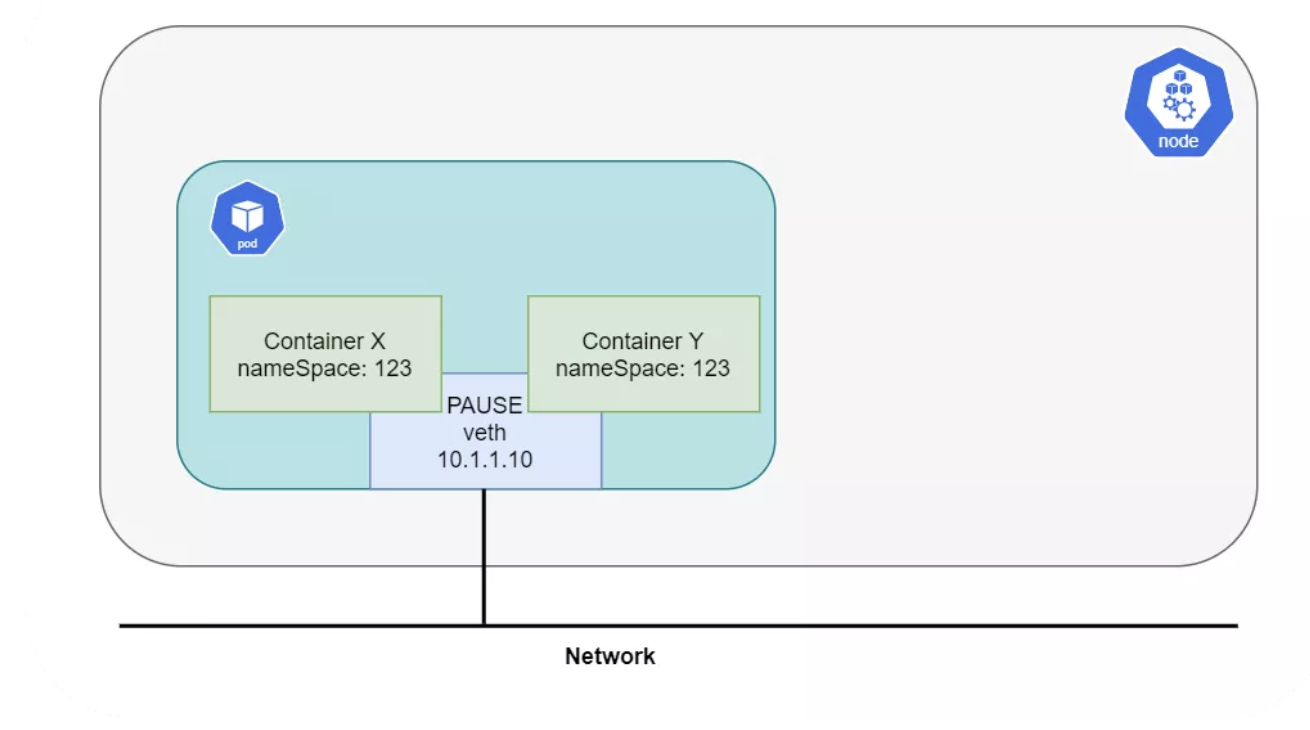
如前所述,CNI 插件是 Kubernetes 网络的重要组件。目前有很多第三方 CNI 插件,Calico[1] 就是其中之一,因为它的易用性和网络能力,得到很多工程师的青睐。它支持很多不同的平台,例如 Kubernetes、OpenShift、Docker EE、OpenStack[2] 以及裸金属服务。Calico Node 组件以 Docker 容器的形式运行在 Kubernetes 的所有 Master 和 Node 节点上。Calico-CNI 插件会直接集成到 Kubernetes 每个节点的 Kubelet 进程中,一旦发现了新建的 Pod,就会将其加入 Calico 网络。
下面的内容会涉及安装、Calico 模块(Felix、BIRD 以及 Confd)和路由模式,但是不会包含网络策略方面的内容。
CNI 的任务
- 创建
veth对,并移入容器 - 鉴别正确的 POD CIDR
- 创建 CNI 配置文件
- IP 地址的分配和管理
- 在容器中加入缺省路由
- 把路由广播给所有 Peer 节点(不适用于 VxLan)
- 在主机上加入路由
- 实施网络策略
其实还有很多别的需求,但是上面几个点是最基础的。看看 Master 和 Worker 节点上的路由表。每个节点都有一个容器,容器有一个 IP 地址和缺省的容器路由。
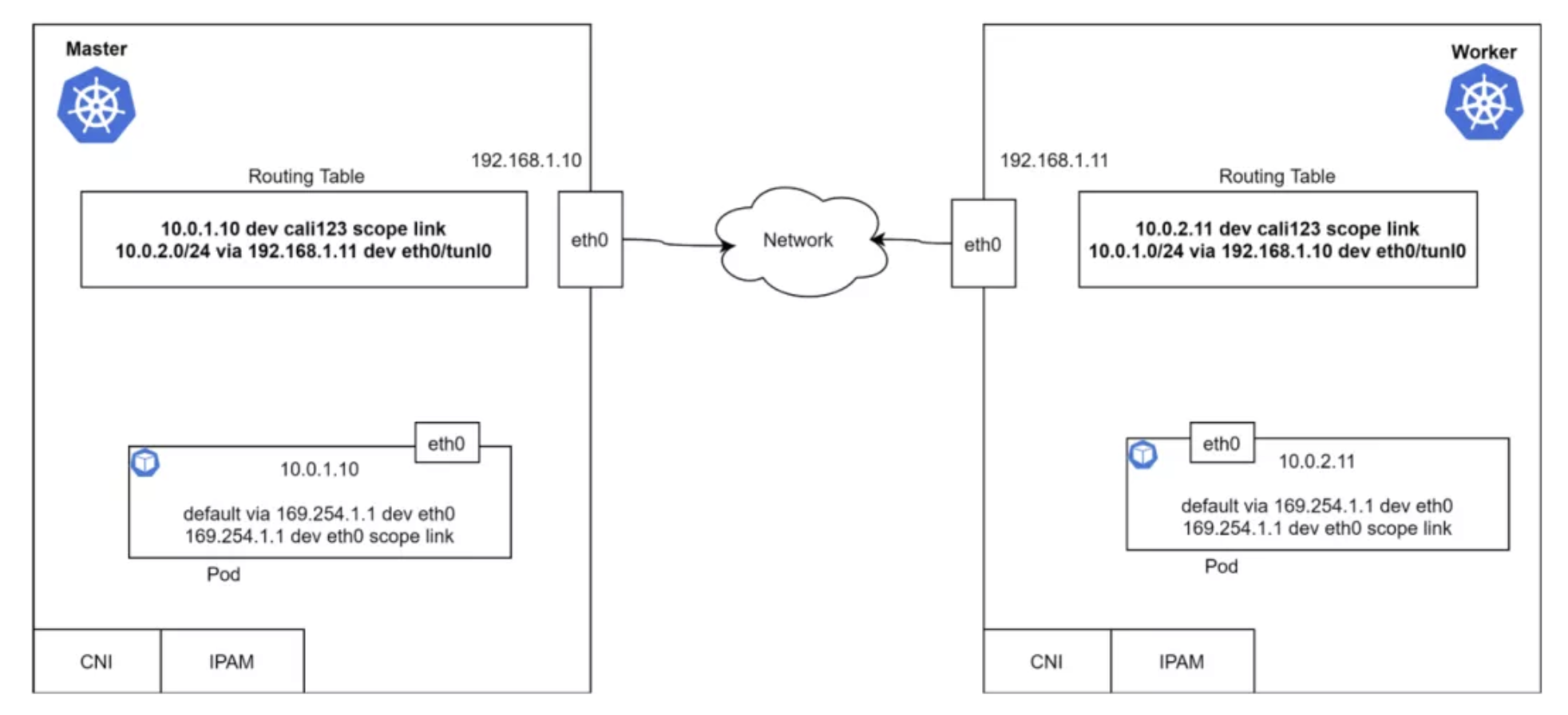
上面的路由表说明,Pod 能够通过 3 层网络进行互通。什么模块负责添加路由,如何获取远端路由呢?为什么这里缺省网关是 169.254.1.1 呢?我们接下来会讨论这些问题。
Calico 的核心包括 Bird、Felix、ConfD、ETCD 以及 Kubernetes API Server。Calico 需要保存一些配置信息,例如 IP 池、端点信息、网络策略等,数据存储位置是可以配置的,本例中我们使用 Kubernetes 进行存储。
BIRD(BGP)
Bird 是一个 BGP 守护进程,运行在每个节点上,负责相互交换路由信息。通常的拓扑关系是节点之间构成的网格:
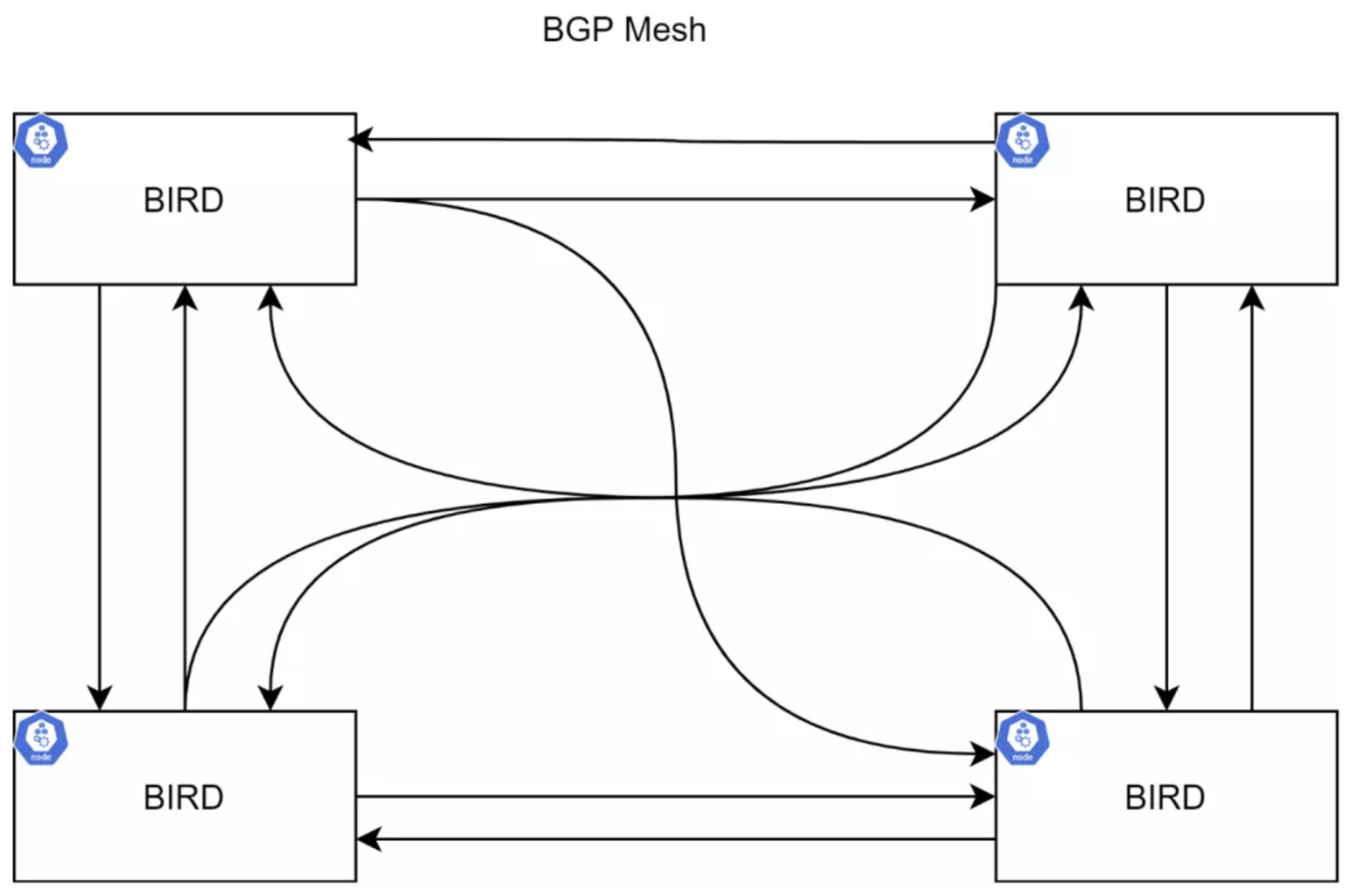
然而集群规模较大的时候,就会很麻烦了。可以使用 Route Reflector(部分 BGP 节点能够配置为 Route Reflector)来完成路由的传播工作,从而降低 BGP 连接数量。路由广播会发送给 Route Reflector,再由 Route Reflector 进行传播,更多信息可以参考 RFC4456。
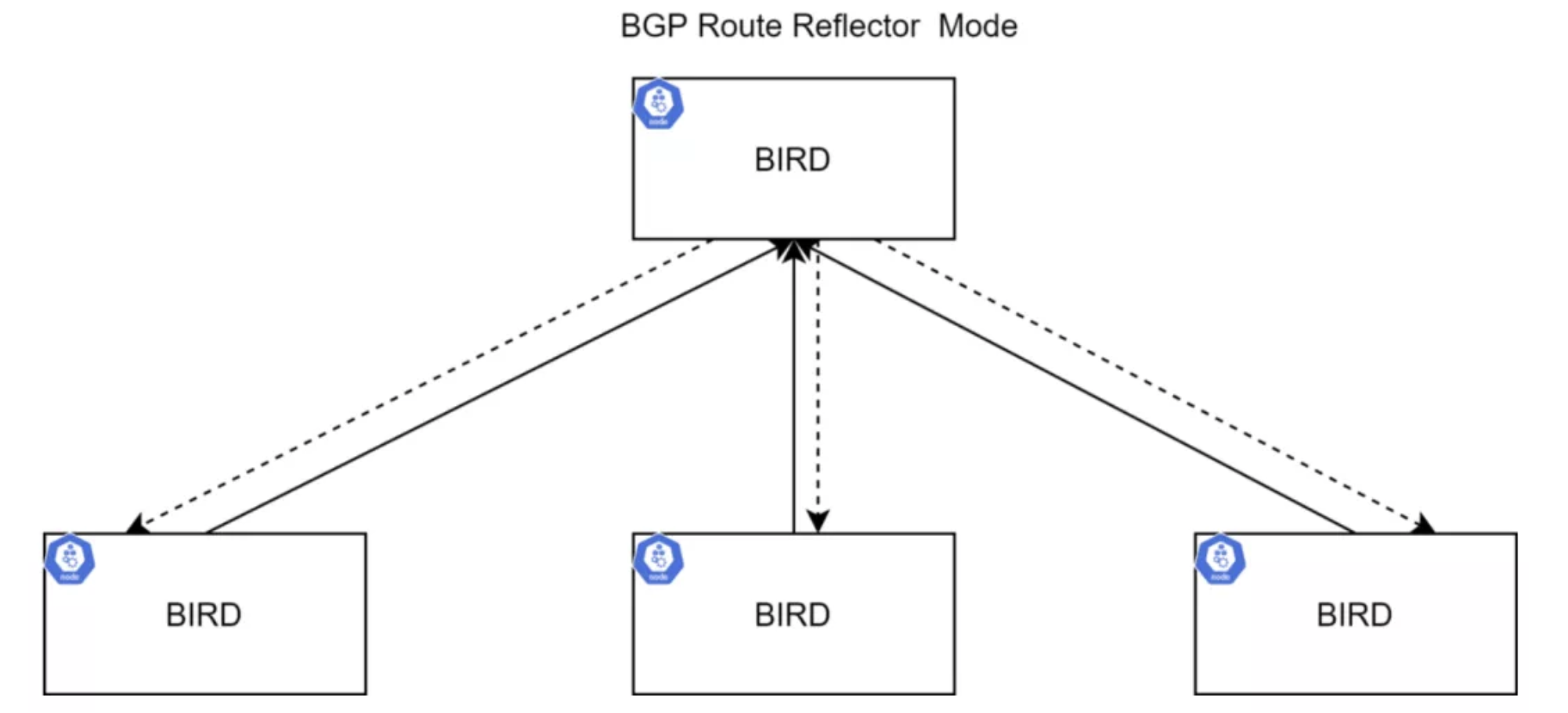
BIRD 实例负责向其它 BIRD 实例传递路由信息。缺省配置方式就是 BGP Mesh,适用于小规模部署。在大规模集群中,建议使用 Route Reflector 来克服这个缺点。可以使用多个 RR 来达成高可用目的,另外还可以使用外部 RR 来替代 BIRD。
ConfD
ConfD 是一个简单的配置管理工具,运行在 Calico Node 容器中。它会从 ETCD 中读取数据(Calico 的 BIRD 配置),并写入磁盘文件。它会循环读取网络和子网,并应用配置数据(CIDR 键),组装为 BIRD 能够使用的配置。这样不管网络如何变化,BIRD 都能够得到通知并在节点之间广播路由。
Felix
Calico Felix 守护进程在 Calico Node 容器中运行,完成如下功能:
- 从 Kubernetes ETCD 中读取信息
- 构建路由表
- 配置 iptables 或者 IPVS
看看集群中所有的 Calico 模块:
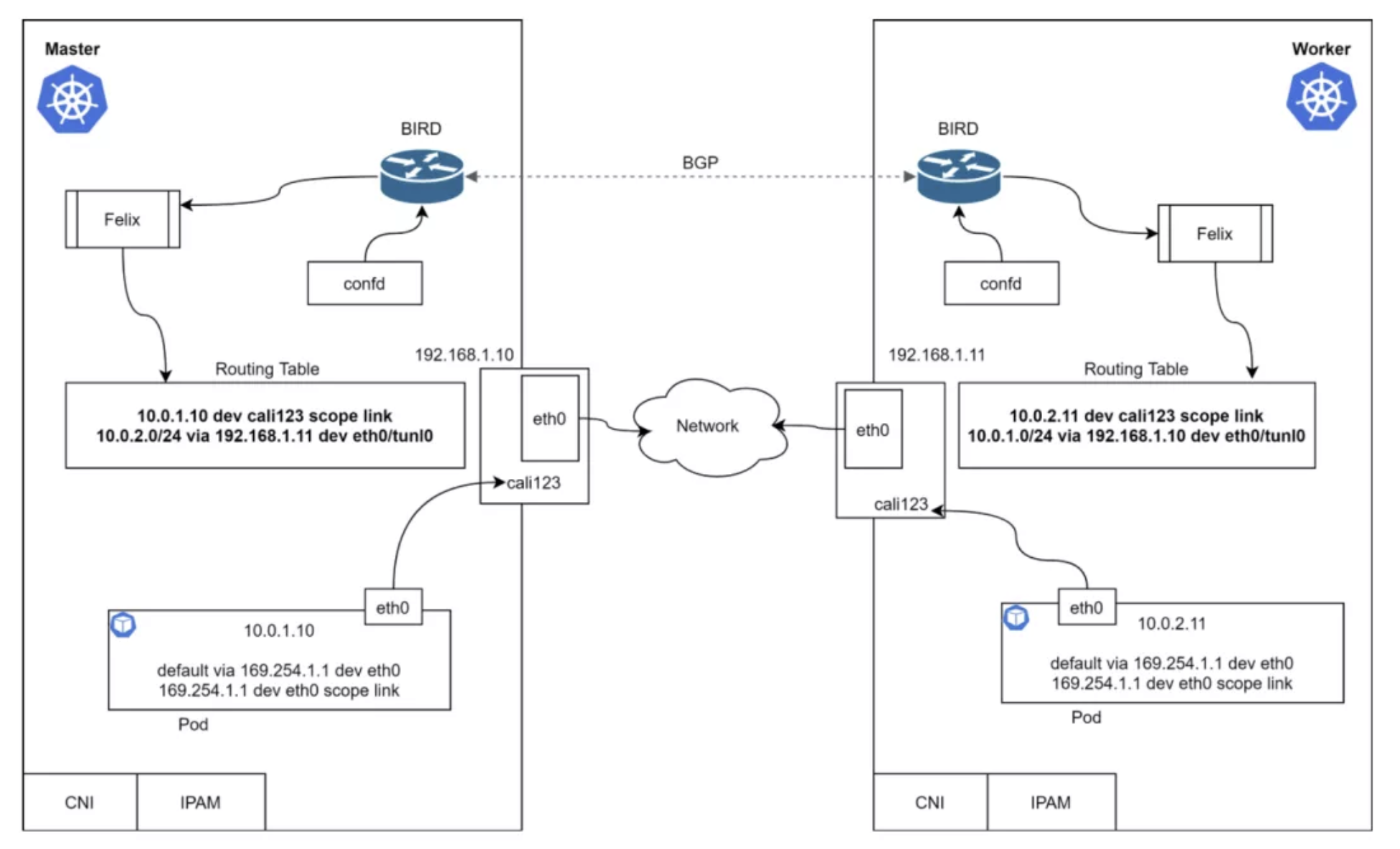
是不是有点不同?veth 的一端是“悬空”的,没有连接。
数据包如何被路由到 Peer 节点的?
- Master 上的 Pod 尝试 Ping
10.0.2.11 - Pod 向网关发送一个 ARP 请求
- 从 ARP 响应中得到 MAC 地址
- 但是谁响应的 ARP 请求?
容器是怎样路由到一个不存在的 IP 的?容器的缺省路由指向了 169.254.1.1。容器的 eth0 需要访问这个地址,因此在使用缺省路由的时候会对这个 IP 进行 ARP 查询。
如果能捕获 ARP 响应信息,会发现 veth 另外一侧的(cali123) MAC 地址。所以到底是怎样响应一个没有 IP 接口的 ARP 请求的呢?答案是 proxy-arp,如果我们检查一下主机侧的 veth 接口,会看到启用了 proxy-arp:
$ cat /proc/sys/net/ipv4/conf/cali123/proxy_arp
1
Proxy ARP 技术能用特定网络上的代理设备来响应针对本网络不存在的 IP 地址的 ARP 查询。这个代理知道流量的目标,会以自己的 MAC 地址进行响应。如此一来,流量就转给 Proxy,通常会被 Proxy 使用其它网络接口或者隧道路由到原定目标。这种以自己 MAC 地址响应其他 IP 地址的 ARP 请求,完成代理任务的行为有时也被称为发布。
仔细看看 Worker 节点:
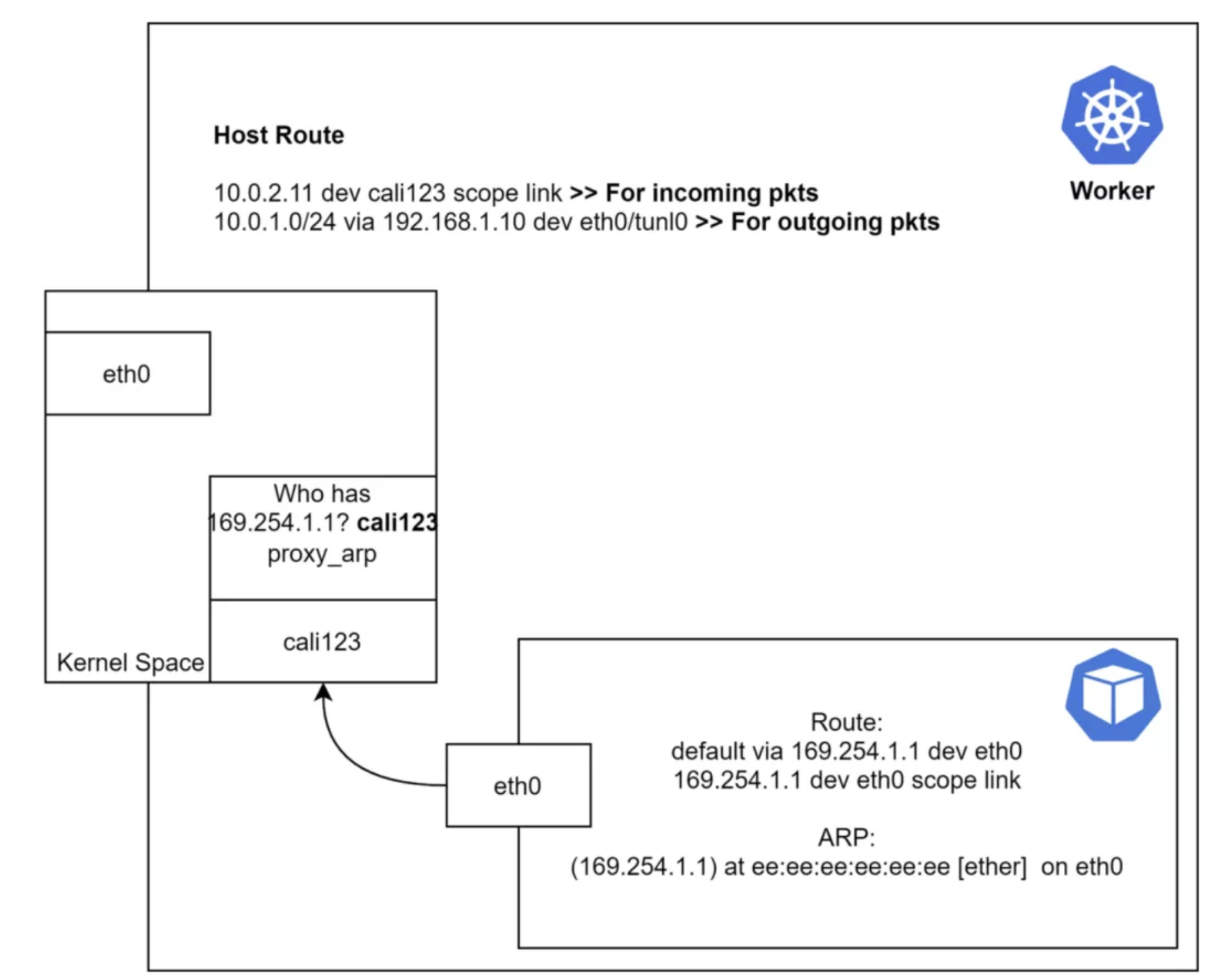
数据包进入内核之后,会根据路由表进行路由。
入栈流量:首先进入Worker 节点内核。内核把数据包发给
cali123。
路由模式
Calico 支持三种路由模式,本节中会对几种模式的优劣和适用场景进行讨论。
-
IP-in-IP:
缺省,有封装行为;
-
Direct/NoEncapMode:
无封包(推荐);
-
VxLan:
有封包(无 BGP)
IP-in-IP
这是一种简单的对 IP 包进行再封包的方式。传输中的数据包带有一个外层头部,其中描述了源主机和目的 IP,还有一个内层头部,包含源 Pod 和目标 IP。目前 Azure 还不支持 IP-IP,因此这种环境中无法使用该模式,建议关掉 IP-IP 以提高性能。
NoEncapMode
这种模式下数据包是用 Pod 发出时的原始格式发出来的。因为没有封包和解包的开销,这种模式比较有性能优势。
AWS 中要使用这种模式需要关闭源 IP 校验。
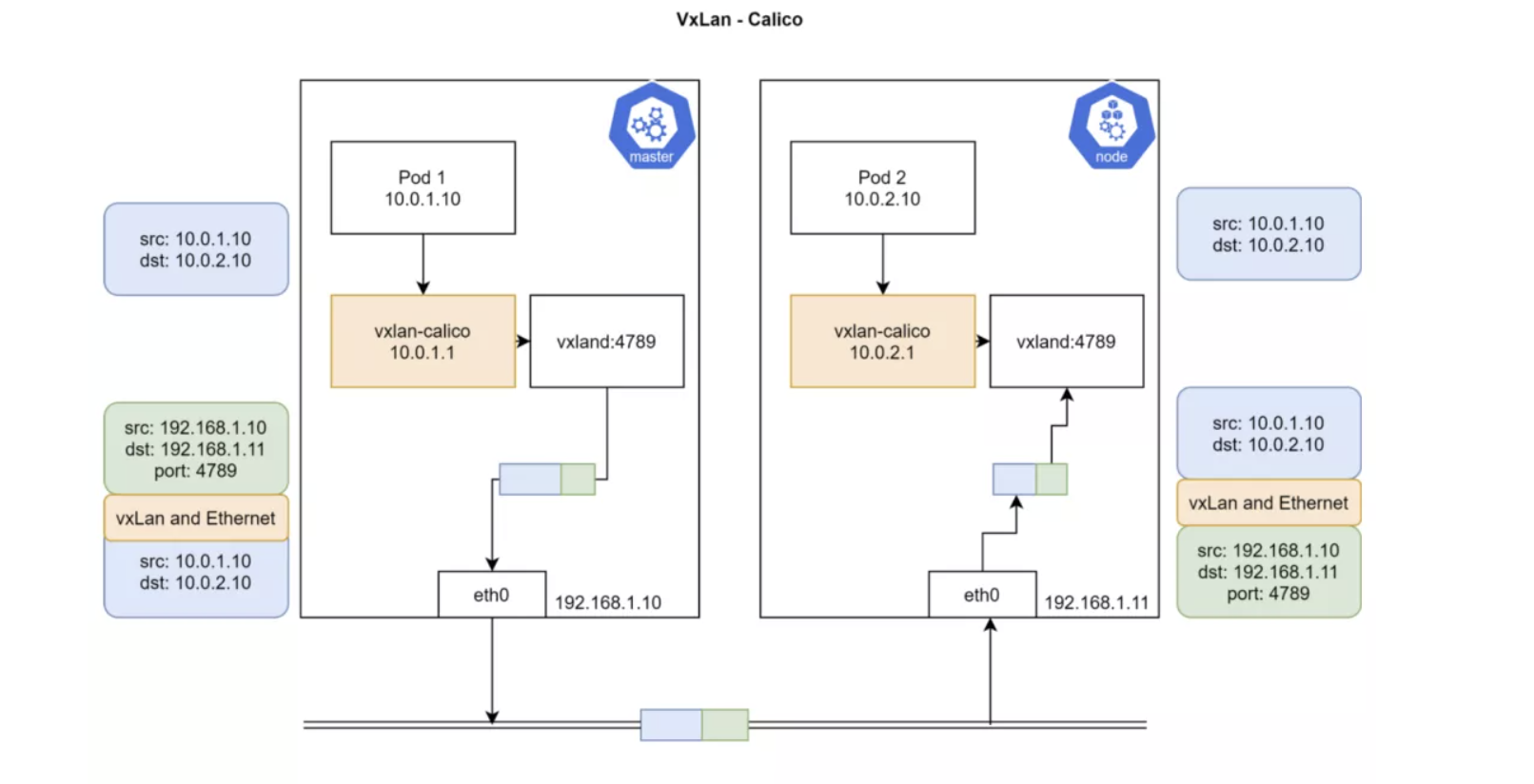
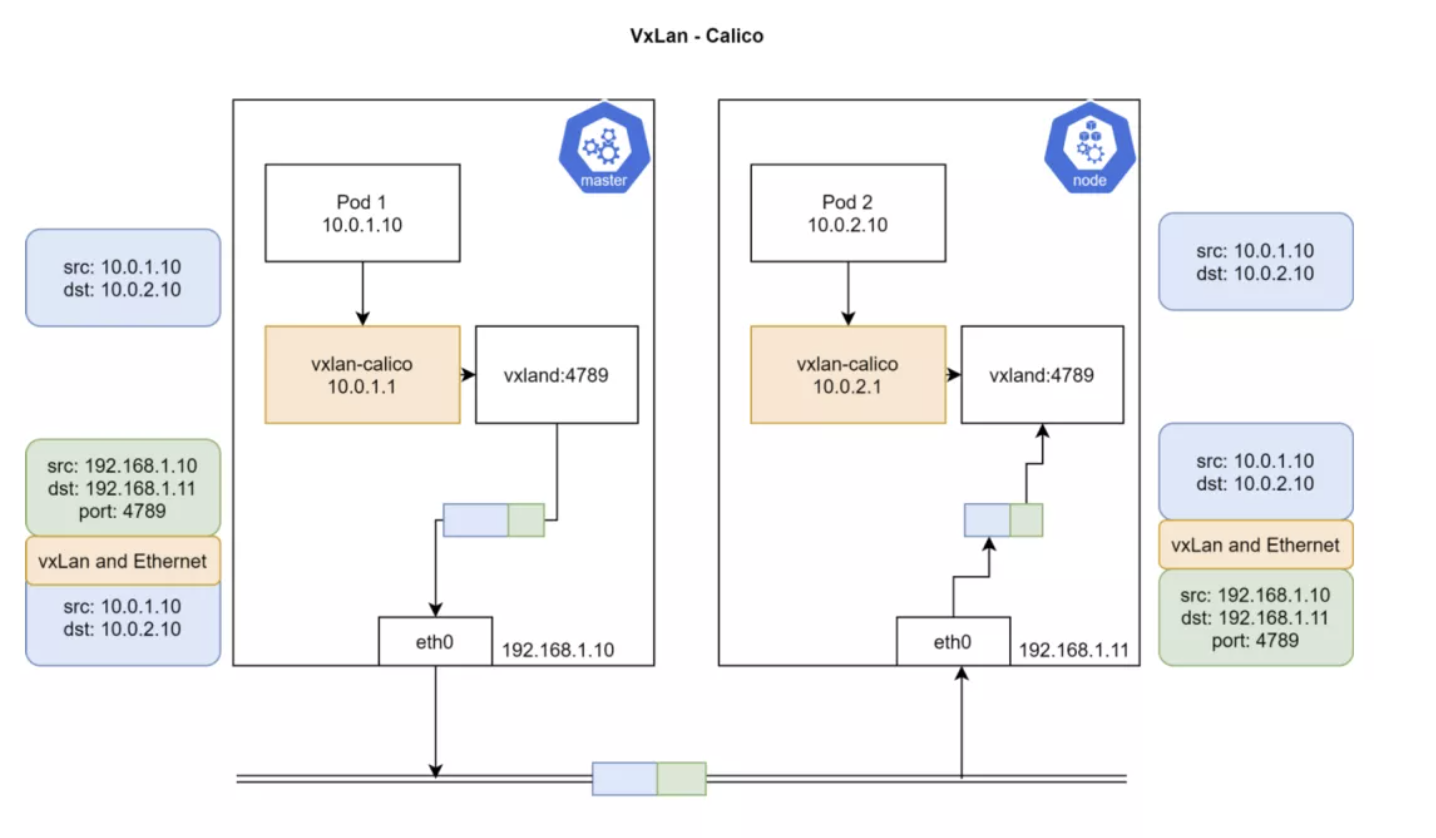
VXLAN
Calico 3.7 以后的版本才支持 VXLAN 路由。
VXLAN 是 Virtual Extensible LAN 的缩写。VXLAN 是一种封包技术,二层数据帧被封装为 UDP 数据包。VXLAN 是一种网络虚拟化技术。当设备在软件定义的数据中心里进行通信时,会在这些设备之间建立 VXLAN 隧道。这些隧道能建立在物理或虚拟交换机之上。这些交换端口被称为 VXLAN Tunnel Endpoints(VTEPs),负责 VXLAN 的封包和解包工作。不支持 VXLAN 的设备可以连接到 VTEP,由 VTEP 提供 VXLAN 的出入转换工作。
VXLAN 对于不支持 IP-in-IP 的网络非常有用,例如 Azure 或者其它不支持 BGP 的数据中心。
演示—— IPIP 和 UnEncapMode
在没安装 Calico 之前检查一下集群:
$ kubectl get nodes
NAME STATUS ROLES AGE VERSION
controlplane NotReady master 40s v1.18.0
node01 NotReady <none> 9s v1.18.0
$ kubectl get pods --all-namespaces
NAMESPACE NAME READY STATUS RESTARTS AGE
kube-system coredns-66bff467f8-52tkd 0/1 Pending 0 32s
kube-system coredns-66bff467f8-g5gjb 0/1 Pending 0 32s
kube-system etcd-controlplane 1/1 Running 0 34s
kube-system kube-apiserver-controlplane 1/1 Running 0 34s
kube-system kube-controller-manager-controlplane 1/1 Running 0 34s
kube-system kube-proxy-b2j4x 1/1 Running 0 13s
kube-system kube-proxy-s46lv 1/1 Running 0 32s
kube-system kube-scheduler-controlplane 1/1 Running 0 33s
检查 CNI 的二进制文件和目录。其中没有任何配置文件或者 Calico 二进制,Calico 安装过程会用加载卷来填充其中的内容:
$ cd /etc/cni
-bash: cd: /etc/cni: No such file or directory
$ cd /opt/cni/bin
$ ls
bridge dhcp flannel host-device host-local ipvlan loopback macvlan portmap ptp sample tuning vlan
在 Master/Worker 节点上检查 ip route:
$ ip route
default via 172.17.0.1 dev ens3
172.17.0.0/16 dev ens3 proto kernel scope link src 172.17.0.32
172.18.0.0/24 dev docker0 proto kernel scope link src 172.18.0.1 linkdown
在集群环境中下载并提交 calico.yaml:
$ curl https://docs.projectcalico.org/manifests/calico.yaml -O
$ kubectl apply -f calico.yaml
看看其中的配置参数:
cni_network_config: |-
{
"name": "k8s-pod-network",
"cniVersion": "0.3.1",
"plugins": [
{
"type": "calico", >>> Calico's CNI plugin
"log_level": "info",
"log_file_path": "/var/log/calico/cni/cni.log",
"datastore_type": "kubernetes",
"nodename": "__KUBERNETES_NODE_NAME__",
"mtu": __CNI_MTU__,
"ipam": {
"type": "calico-ipam" >>> Calico's IPAM instaed of default IPAM
},
"policy": {
"type": "k8s"
},
"kubernetes": {
"kubeconfig": "__KUBECONFIG_FILEPATH__"
}
},
{
"type": "portmap",
"snat": true,
"capabilities": {"portMappings": true}
},
{
"type": "bandwidth",
"capabilities": {"bandwidth": true}
}
]
}
# Enable IPIP
- name: CALICO_IPV4POOL_IPIP
value: "Always" >> Set this to 'Never' to disable IP-IP
# Enable or Disable VXLAN on the default IP pool.
- name: CALICO_IPV4POOL_VXLAN
value: "Never"
安装完毕之后,检查 Pod 和节点状态。
$ kubectl get pods --all-namespaces
NAMESPACE NAME READY STATUS RESTARTS AGE
kube-system calico-kube-controllers-799fb94867-6qj77 0/1 ContainerCreating 0 21s
kube-system calico-node-bzttq 0/1 PodInitializing 0 21s
kube-system calico-node-r6bwj 0/1 PodInitializing 0 21s
kube-system coredns-66bff467f8-52tkd 0/1 Pending 0 7m5s
kube-system coredns-66bff467f8-g5gjb 0/1 ContainerCreating 0 7m5s
kube-system etcd-controlplane 1/1 Running 0 7m7s
kube-system kube-apiserver-controlplane 1/1 Running 0 7m7s
kube-system kube-controller-manager-controlplane 1/1 Running 0 7m7s
kube-system kube-proxy-b2j4x 1/1 Running 0 6m46s
kube-system kube-proxy-s46lv 1/1 Running 0 7m5s
kube-system kube-scheduler-controlplane 1/1 Running 0 7m6s
$ kubectl get nodes
NAME STATUS ROLES AGE VERSION
controlplane Ready master 7m30s v1.18.0
node01 Ready <none> 6m59s v1.18.0
Kubelet 需要 CNI 的配置文件来设置网络:
$ cd /etc/cni/net.d/
$ ls
10-calico.conflist calico-kubeconfig
$
$
$ cat 10-calico.conflist
{
"name": "k8s-pod-network",
"cniVersion": "0.3.1",
"plugins": [
{
"type": "calico",
"log_level": "info",
"log_file_path": "/var/log/calico/cni/cni.log",
"datastore_type": "kubernetes",
"nodename": "controlplane",
"mtu": 1440,
"ipam": {
"type": "calico-ipam"
},
"policy": {
"type": "k8s"
},
"kubernetes": {
"kubeconfig": "/etc/cni/net.d/calico-kubeconfig"
}
},
{
"type": "portmap",
"snat": true,
"capabilities": {"portMappings": true}
},
{
"type": "bandwidth",
"capabilities": {"bandwidth": true}
}
]
}
检查 CNI 的二进制文件:
$ ls
bandwidth bridge calico calico-ipam dhcp flannel host-device host-local install ipvlan loopback macvlan portmap ptp sample tuning vlan
安装 calicoctl 来获取 Calico 的更多信息并能修改 Calico 配置:
$ cd /usr/local/bin/
$ curl -O -L https://github.com/projectcalico/calicoctl/releases/download/v3.16.3/calicoctl
% Total % Received % Xferd Average Speed Time Time Time Current
Dload Upload Total Spent Left Speed
100 633 100 633 0 0 3087 0 --:--:-- --:--:-- --:--:-- 3087
100 38.4M 100 38.4M 0 0 5072k 0 0:00:07 0:00:07 --:--:-- 4325k
$ chmod +x calicoctl
$ export DATASTORE_TYPE=kubernetes
$ export KUBECONFIG=~/.kube/config
# Check endpoints - it will be empty as we have't deployed any POD
$ calicoctl get workloadendpoints
WORKLOAD NODE NETWORKS INTERFACE
检查 BGP Peer 的状态,会看到 Worker 节点是一个 Peer。
$ calicoctl node status
Calico process is running.
IPv4 BGP status
+--------------+-------------------+-------+----------+-------------+
| PEER ADDRESS | PEER TYPE | STATE | SINCE | INFO |
+--------------+-------------------+-------+----------+-------------+
| 172.17.0.40 | node-to-node mesh | up | 00:24:04 | Established |
+--------------+-------------------+-------+----------+-------------+
创建一个两副本 Pod,并设置 tolerations,使之可以运行在 Master 节点:
apiVersion: apps/v1
kind: Deployment
metadata:
name: busybox-deployment
spec:
selector:
matchLabels:
app: busybox
replicas: 2
template:
metadata:
labels:
app: busybox
spec:
tolerations:
- key: "node-role.kubernetes.io/master"
operator: "Exists"
effect: "NoSchedule"
containers:
- name: busybox
image: busybox
command: ["sleep"]
args: ["10000"]
获取 Pod 和端点状态:
$ kubectl get pods -o wide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
busybox-deployment-8c7dc8548-btnkv 1/1 Running 0 6s 192.168.196.131 node01 <none> <none>
busybox-deployment-8c7dc8548-x6ljh 1/1 Running 0 6s 192.168.49.66 controlplane <none> <none>
$ calicoctl get workloadendpoints
WORKLOAD NODE NETWORKS INTERFACE
busybox-deployment-8c7dc8548-btnkv node01 192.168.196.131/32 calib673e730d42
busybox-deployment-8c7dc8548-x6ljh controlplane 192.168.49.66/32 cali9861acf9f07
获取 Pod 所在主机上的 VETH 信息:
$ ifconfig cali9861acf9f07
cali9861acf9f07: flags=4163<UP,BROADCAST,RUNNING,MULTICAST> mtu 1440
inet6 fe80::ecee:eeff:feee:eeee prefixlen 64 scopeid 0x20<link>
ether ee:ee:ee:ee:ee:ee txqueuelen 0 (Ethernet)
RX packets 0 bytes 0 (0.0 B)
RX errors 0 dropped 0 overruns 0 frame 0
TX packets 5 bytes 446 (446.0 B)
TX errors 0 dropped 0 overruns 0 carrier 0 collisions 0
获取 Pod 网络界面的信息:
$ kubectl exec busybox-deployment-8c7dc8548-x6ljh -- ifconfig
eth0 Link encap:Ethernet HWaddr 92:7E:C4:15:B9:82
inet addr:192.168.49.66 Bcast:192.168.49.66 Mask:255.255.255.255
UP BROADCAST RUNNING MULTICAST MTU:1440 Metric:1
RX packets:5 errors:0 dropped:0 overruns:0 frame:0
TX packets:0 errors:0 dropped:0 overruns:0 carrier:0
collisions:0 txqueuelen:0
RX bytes:446 (446.0 B) TX bytes:0 (0.0 B)
lo Link encap:Local Loopback
inet addr:127.0.0.1 Mask:255.0.0.0
UP LOOPBACK RUNNING MTU:65536 Metric:1
RX packets:0 errors:0 dropped:0 overruns:0 frame:0
TX packets:0 errors:0 dropped:0 overruns:0 carrier:0
collisions:0 txqueuelen:1000
RX bytes:0 (0.0 B) TX bytes:0 (0.0 B)
$ kubectl exec busybox-deployment-8c7dc8548-x6ljh -- ip route
default via 169.254.1.1 dev eth0
169.254.1.1 dev eth0 scope link
$ kubectl exec busybox-deployment-8c7dc8548-x6ljh -- arp
获取主节点路由:
$ ip route
default via 172.17.0.1 dev ens3
172.17.0.0/16 dev ens3 proto kernel scope link src 172.17.0.32
172.18.0.0/24 dev docker0 proto kernel scope link src 172.18.0.1 linkdown
blackhole 192.168.49.64/26 proto bird
192.168.49.65 dev calic22dbe57533 scope link
192.168.49.66 dev cali9861acf9f07 scope link
192.168.196.128/26 via 172.17.0.40 dev tunl0 proto bird onlink
尝试 Ping Worker 节点来触发 ARP:
$ kubectl exec busybox-deployment-8c7dc8548-x6ljh -- ping 192.168.196.131 -c 1
PING 192.168.196.131 (192.168.196.131): 56 data bytes
64 bytes from 192.168.196.131: seq=0 ttl=62 time=0.823 ms
$ kubectl exec busybox-deployment-8c7dc8548-x6ljh -- arp
? (169.254.1.1) at ee:ee:ee:ee:ee:ee [ether] on eth0
注意上面的 MAC 地址。发出流量时,内核根据 IP 路由将数据包写入 tunl0,Proxy ARP 的配置:
$ cat /proc/sys/net/ipv4/conf/cali9861acf9f07/proxy_arp
1
六、目标节点如何处理数据包
node01 $ ip route
default via 172.17.0.1 dev ens3
172.17.0.0/16 dev ens3 proto kernel scope link src 172.17.0.40
172.18.0.0/24 dev docker0 proto kernel scope link src 172.18.0.1 linkdown
192.168.49.64/26 via 172.17.0.32 dev tunl0 proto bird onlink
blackhole 192.168.196.128/26 proto bird
192.168.196.129 dev calid4f00d97cb5 scope link
192.168.196.130 dev cali257578b48b6 scope link
192.168.196.131 dev calib673e730d42 scope link
接收到数据包之后,内核会根据路由表将数据包发给对应的 veth。
如果抓包的话会看出 IP-IP 协议。据我所知,Azure 不支持 IP-IP,也就是说我们无法在这种环境里使用 IP-IP。关闭 IP-IP 能获得更高性能,下面一节尝试一下。
禁用 IP-IP
更新 ippool.yaml 设置 IPIP 为 Never,然后用 calicoctl 应用配置:
$ calicoctl get ippool default-ipv4-ippool -o yaml > ippool.yaml
$ vi ippool.yaml
...
$ calicoctl apply -f ippool.yaml
Successfully applied 1 'IPPool' resource(s)
再次检查 ip route:
$ ip route
default via 172.17.0.1 dev ens3
172.17.0.0/16 dev ens3 proto kernel scope link src 172.17.0.32
172.18.0.0/24 dev docker0 proto kernel scope link src 172.18.0.1 linkdown
blackhole 192.168.49.64/26 proto bird
192.168.49.65 dev calic22dbe57533 scope link
192.168.49.66 dev cali9861acf9f07 scope link
192.168.196.128/26 via 172.17.0.40 dev ens3 proto bird
设备不再是 tunl0,而是变成 Master 节点的管理界面(ens3)。
Ping 一下 Worker 节点,验证工作情况,此时不再使用 IPIP 协议:
$ kubectl exec busybox-deployment-8c7dc8548-x6ljh -- ping 192.168.196.131 -c 1
PING 192.168.196.131 (192.168.196.131): 56 data bytes
64 bytes from 192.168.196.131: seq=0 ttl=62 time=0.653 ms
--- 192.168.196.131 ping statistics ---
1 packets transmitted, 1 packets received, 0% packet loss
round-trip min/avg/max = 0.653/0.653/0.653 ms
注意在 AWS 环境中使用这种模式需要禁用源 IP 检查。
演示 VXLAN
重新进行集群初始化,并下载 calico.yaml 文件,进行如下变更:
从 livenessProbe 和 readinessProbe 中删除 bird:
livenessProbe:
exec:
command:
- /bin/calico-node
- -felix-live
- -bird-live >> Remove this
periodSeconds: 10
initialDelaySeconds: 10
failureThreshold: 6
readinessProbe:
exec:
command:
- /bin/calico-node
- -felix-ready
- -bird-ready >> Remove this
把 calico_backend 修改为 vxlan,不再需要 BGP:
kind: ConfigMap
apiVersion: v1
metadata:
name: calico-config
namespace: kube-system
data:
# Typha is disabled.
typha_service_name: "none"
# Configure the backend to use.
calico_backend: "vxlan"
禁用 IPIP:
# Enable IPIP
- name: CALICO_IPV4POOL_IPIP
value: "Never" >> Set this to 'Never' to disable IP-IP
# Enable or Disable VXLAN on the default IP pool.
- name: CALICO_IPV4POOL_VXLAN
value: "Never"
应用这个 YAML:
$ ip route
default via 172.17.0.1 dev ens3
172.17.0.0/16 dev ens3 proto kernel scope link src 172.17.0.15
172.18.0.0/24 dev docker0 proto kernel scope link src 172.18.0.1 linkdown
192.168.49.65 dev calif5cc38277c7 scope link
192.168.49.66 dev cali840c047460a scope link
192.168.196.128/26 via 192.168.196.128 dev vxlan.calico onlink
vxlan.calico: flags=4163<UP,BROADCAST,RUNNING,MULTICAST> mtu 1440
inet 192.168.196.128 netmask 255.255.255.255 broadcast 192.168.196.128
inet6 fe80::64aa:99ff:fe2f:dc24 prefixlen 64 scopeid 0x20<link>
ether 66:aa:99:2f:dc:24 txqueuelen 0 (Ethernet)
RX packets 0 bytes 0 (0.0 B)
RX errors 0 dropped 0 overruns 0 frame 0
TX packets 0 bytes 0 (0.0 B)
TX errors 0 dropped 11 overruns 0 carrier 0 collisions 0
获取 Pod 状态:
$ kubectl get pods -o wide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
busybox-deployment-8c7dc8548-8bxnw 1/1 Running 0 11s 192.168.49.67 controlplane <none> <none>
busybox-deployment-8c7dc8548-kmxst 1/1 Running 0 11s 192.168.196.130 node01 <none> <none>
查看 ip route:
$ kubectl exec busybox-deployment-8c7dc8548-8bxnw -- ip route
default via 169.254.1.1 dev eth0
169.254.1.1 dev eth0 scope link
执行 Ping,触发 ARP 查询:
$ kubectl exec busybox-deployment-8c7dc8548-8bxnw -- arp
master $ kubectl exec busybox-deployment-8c7dc8548-8bxnw -- ping 8.8.8.8
PING 8.8.8.8 (8.8.8.8): 56 data bytes
64 bytes from 8.8.8.8: seq=0 ttl=116 time=3.786 ms
^C
$ kubectl exec busybox-deployment-8c7dc8548-8bxnw -- arp
? (169.254.1.1) at ee:ee:ee:ee:ee:ee [ether] on eth0
概念和前一种模式相似,区别在于数据包抵达 vxland 的时候,会把节点 IP 以及 MAC 地址封装并发送。另外 vxland 的 UDP 端口是 4789。这里会从 etcd 获取可用节点以及节点支持的 IP 范围,从而让 vxlan-calico 据此构建数据包。
VxLan 模式需要更多系统开销
接下来我们会讨论一下 Kubernetes 的 kube-proxy 是如何使用 iptables 控制流量的。注意,kube-proxy + iptables 的组合并非完成该任务的唯一选择。
我们会从 Kubernetes 的多种通信模型和实现开始,如果读者已经了解了 Service、ClusterIP 以及 NodePort 的概念,可以直接跳到 kube-proxy/iptables 一节。
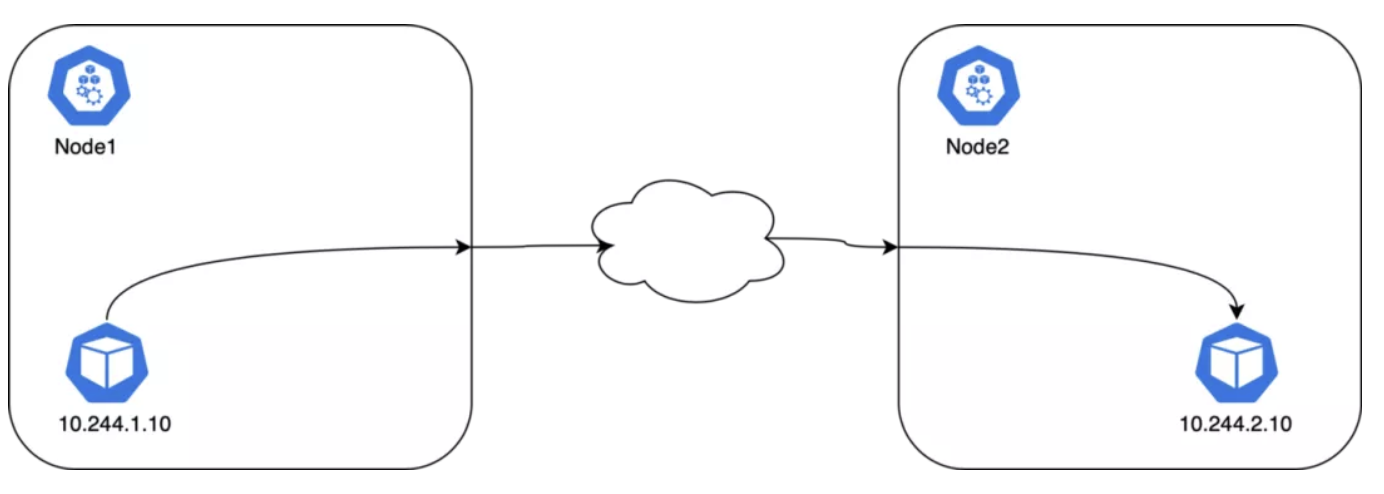
Pod 到 Pod
CNI 会配置节点和 Pod 的路由,kube-proxy 不会介入 Pod 到 Pod 之间的通信过程。所有的容器都无需 NAT 就能互相通信;节点和容器之间的通信也是无需 NAT 的。
Pod 的 IP 地址是不固定的(也有办法做成静态 IP,但是缺省配置是不提供这种保障的)。在 Pod 重启时 CNI 会给他分配新的 IP 地址,CNI 不负责维护 IP 地址和 Pod 的映射。Pod 名称在 Deployment 之中也是不固定的。
Deployment 中的 Pod 是无状态的,一个应用可能会有多个 Pod 副本,因此需要一个负载均衡之类的东西来负责对外开放服务,Kubernetes 中的 Service 对象负责完成这个任务。
Pod 到外部
Kubernetes 会使用 SNAT 完成从 Pod 向外发出的访问。SNAT 会将 Pod 的内部 IP:Port 替换为主机的 IP:Port。返回数据包到达节点时,IP:Port 又会换回 Pod。这个过程对于原始 Pod 是透明无感知的。
Pod 到 Service
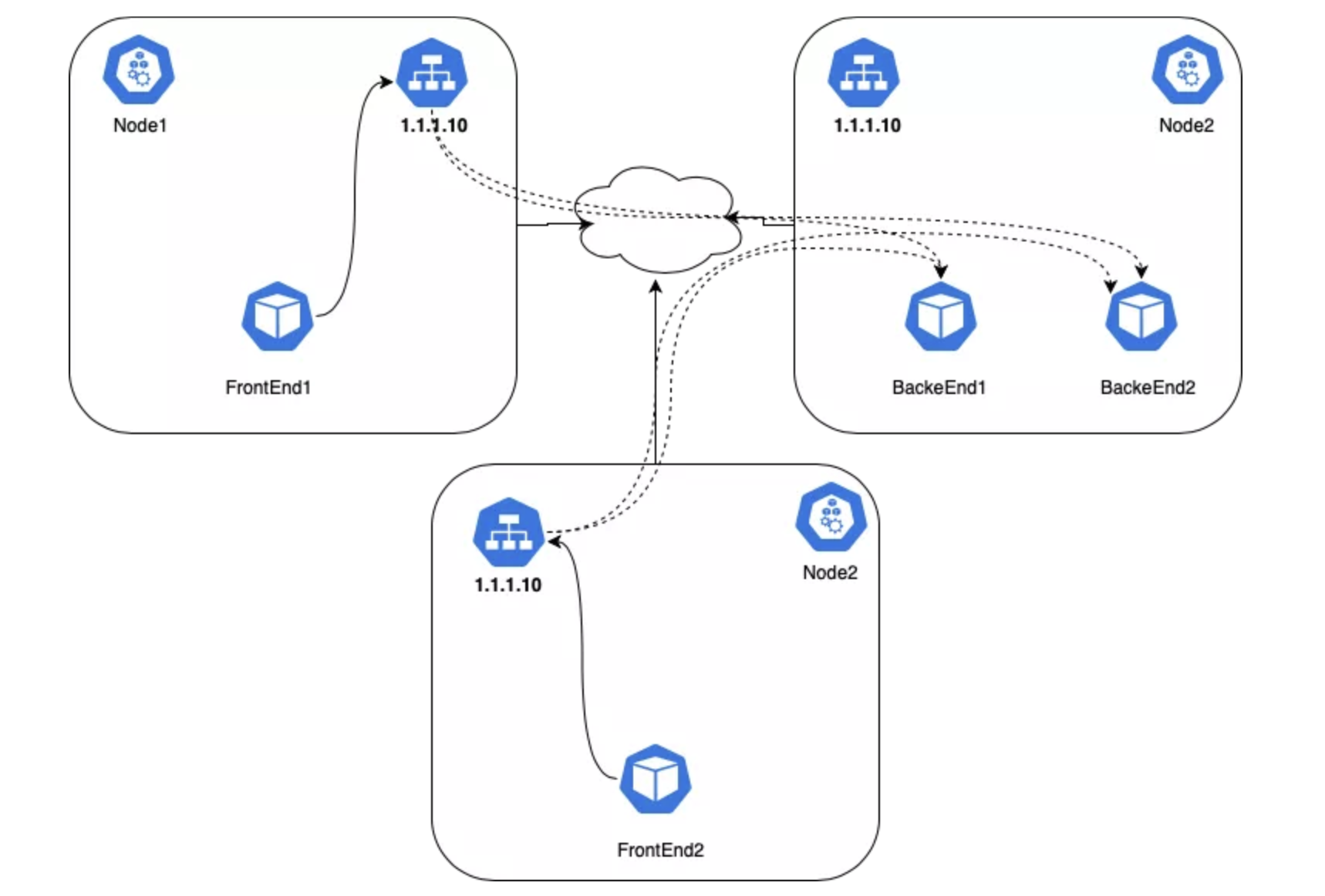
Cluster IP
Kubernetes 有一个叫做 Service 的对象,是一个通向 Pod 的 4 层负载均衡。Service 对象有很多类型,最基本的类型叫做 ClusterIP,这种类型的 Service 有一个唯一的 VIP 地址,其路由范围仅在集群内部有效。
Kubernetes 集群中,Pod 可能发生移动、重启、升级或者扩缩容,因此向应用 Pod 发送流量是有困难的,另外应用通常有多个副本,我们需要一些方法来进行负载均衡。
Kubernetes 使用 Service 对象来解决这个问题。Service 是一个 API 对象,它用一个虚拟 IP 映射到一组 Pod。另外 Kubernetes 为每个 Service 的名称及其虚拟 IP 建立了 DNS 记录,因此可以轻松地根据名称进行寻址。
虚拟 IP 到 Pod IP 的转换是通过每个节点上的 kube-proxy 完成的。在 Pod 向外发起通信时,这个进程会通过 iptables 或者 IPVS 自动把 VIP 转为 Pod IP,每个连接都有跟踪,所以数据包返回时候,地址还能够被正确地转回原样。IPVS 和 iptables 在 VIP 和 Pod IP 之间承担着负载均衡的角色,IPVS 能够提供更多的负载均衡算法。虚拟 IP 并不存在于网络接口上,而是在 iptable 中:
FrontEnd Deployment:
apiVersion: apps/v1
kind: Deployment
metadata:
name: webapp
labels:
app: webapp
spec:
replicas: 2
selector:
matchLabels:
app: webapp
template:
metadata:
labels:
app: webapp
spec:
containers:
- name: nginx
image: nginx:1.14.2
imagePullPolicy: IfNotPresent
ports:
- containerPort: 80
Backend Deployment:
apiVersion: apps/v1
kind: Deployment
metadata:
name: auth
labels:
app: auth
spec:
replicas: 2
selector:
matchLabels:
app: auth
template:
metadata:
labels:
app: auth
spec:
containers:
- name: nginx
image: nginx:1.14.2
imagePullPolicy: IfNotPresent
ports:
- containerPort: 80
Service:
---
apiVersion: v1
kind: Service
metadata:
name: frontend
labels:
app: frontend
spec:
ports:
- port: 80
protocol: TCP
type: ClusterIP
selector:
app: webapp
---
apiVersion: v1
kind: Service
metadata:
name: backend
labels:
app: backend
spec:
ports:
- port: 80
protocol: TCP
type: ClusterIP
selector:
app: auth
...
现在 FrontEnd Pod 能够通过 ClusterIP 或者 DNS 名称来访问 Backend 了。CoreDNS 这样的 DNS 服务器具备 Kubernetes 集群感知的能力,他们会对 Kubernetes API 进行监控,一旦新建了 Service,就会新建对应的 DNS 记录。如果集群中启用的 DNS,所有 Pod 都能够自动的根据 DNS 名称来解析到 Service。
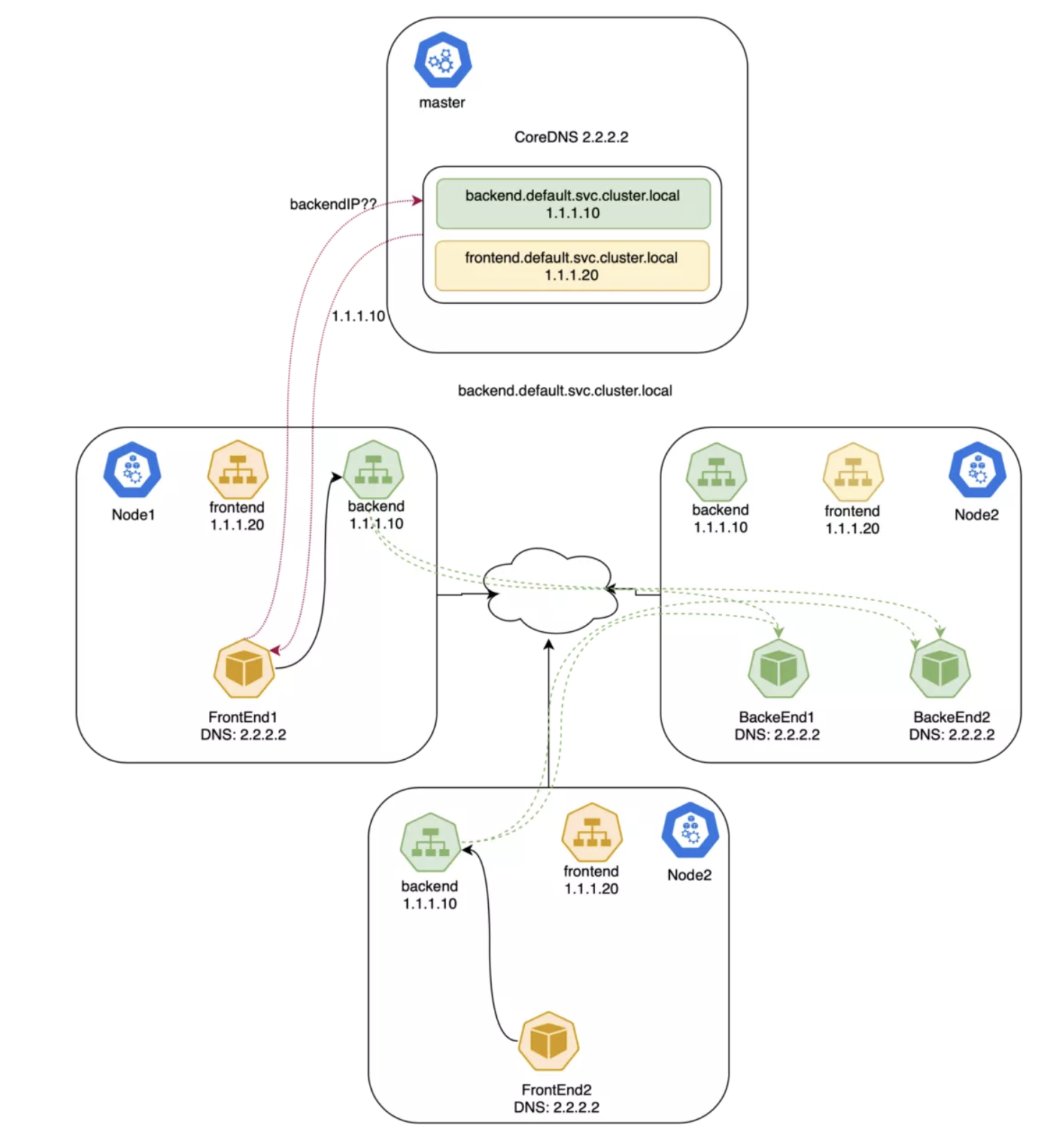
NodePort(外部到 Pod)
在集群内部可以用 DNS 访问 Service。然而 Service 的 IP 是私有的和虚拟的,所以集群外是无法访问的。
试试看从外部访问 frontEnd 的 Pod(此时还没有给 frontEnd 创建 Service):
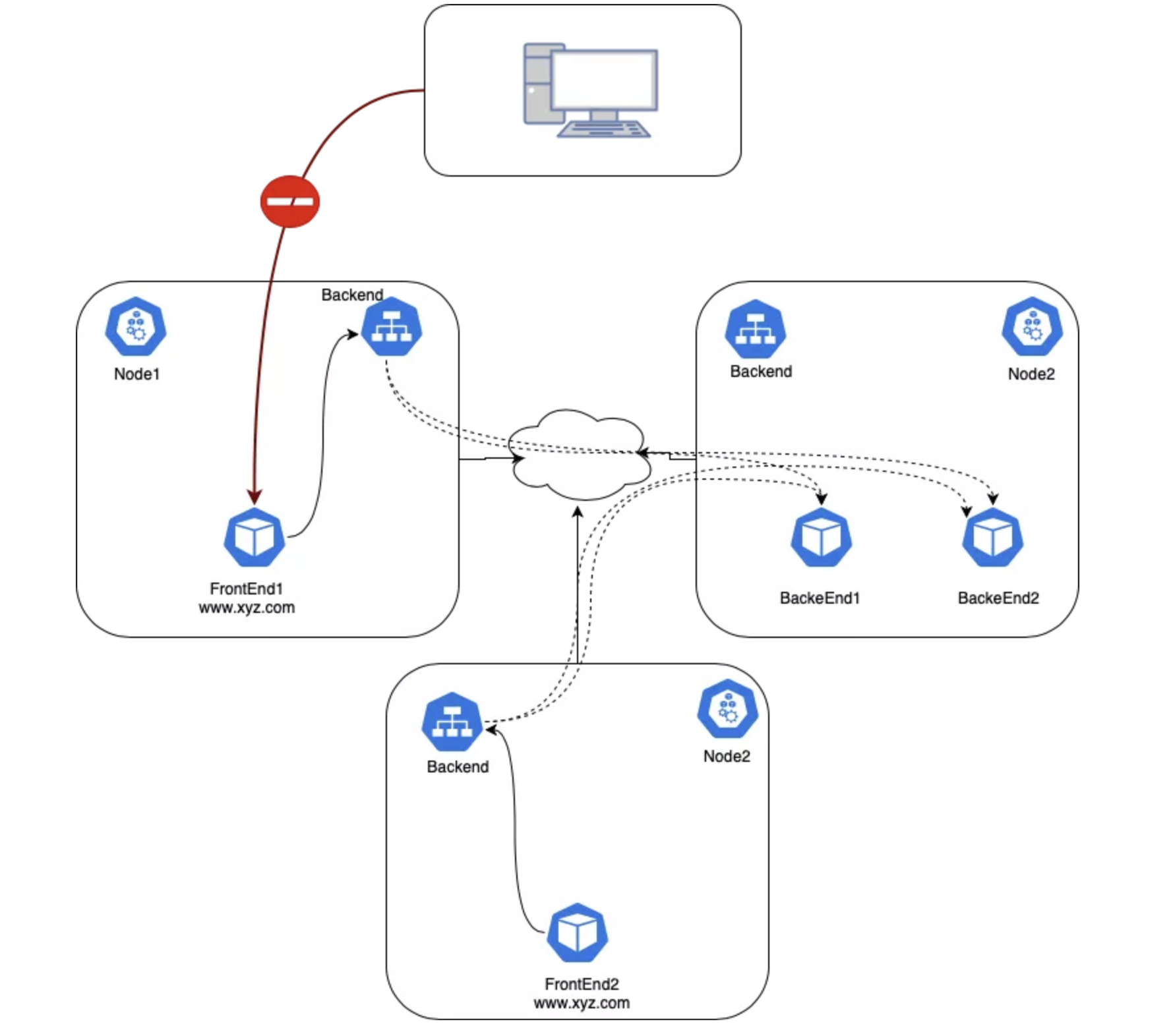
Pod IP 是私有的,无法路由。
接下来创建一个 NodePort 类型的 Service 把 FrontEnd 服务开放给外部世界。如果把 type 字段设置为 NodePort,Kubernetes 控制面使用 --service-node-port-range 参数为 NodePort 服务分配了一个端口范围。每个节点都会会把这个端口映射给特定的服务。Service 使用 .spec.ports[*].nodePort 字段来指定该端口:
---
apiVersion: v1
kind: Service
metadata:
name: frontend
spec:
type: NodePort
selector:
app: webapp
ports:
# By default and for convenience, the `targetPort` is set to the same value as the `port` field.
- port: 80
targetPort: 80
# Optional field
# By default and for convenience, the Kubernetes control plane will allocate a port from a range (default: 30000-32767)
nodePort: 31380
...
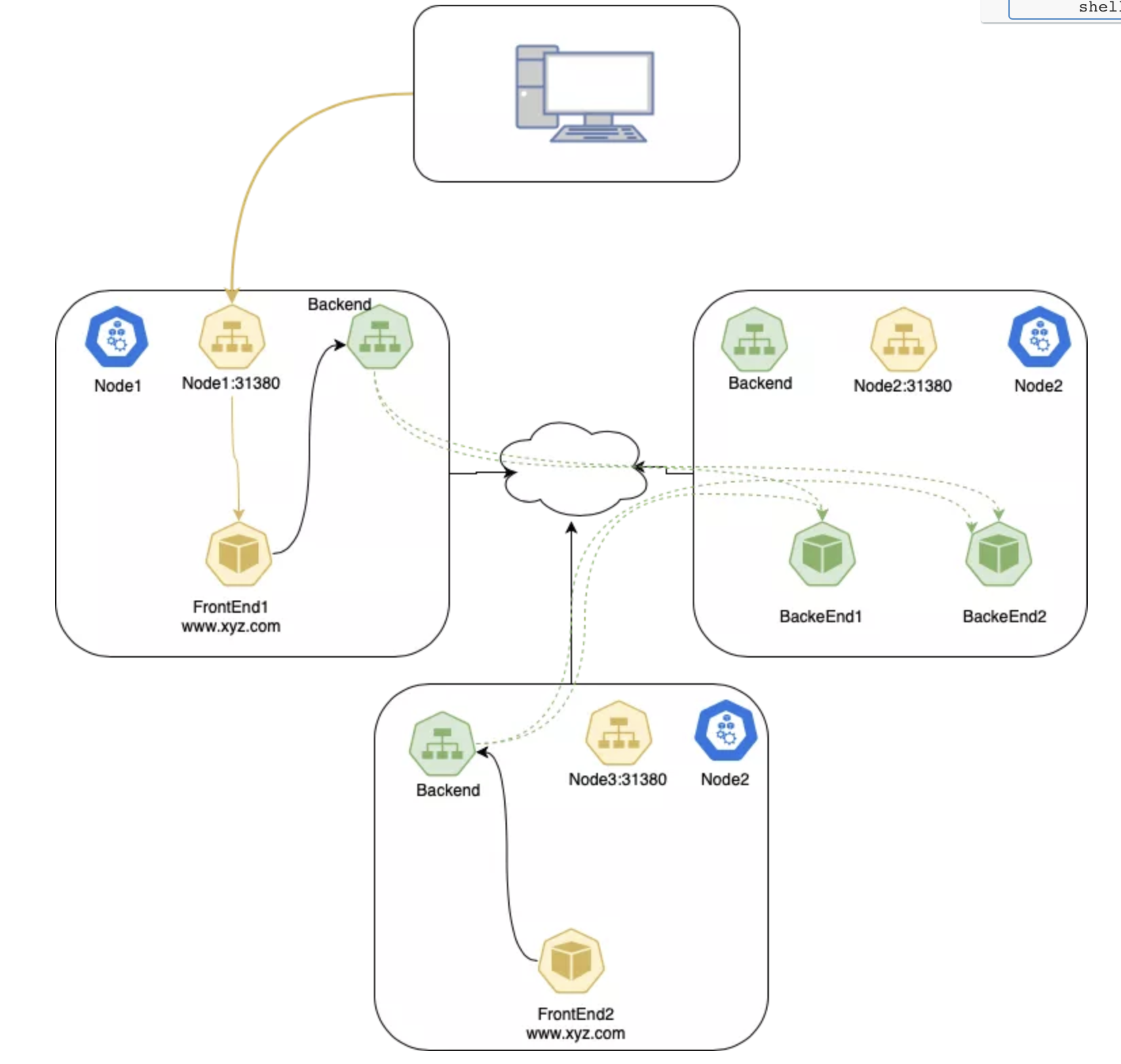
这样就可以在集群外使用任意节点的 nodePort 来访问服务了。还可以给 nodePort 赋值以指定特定开放端口。这种情况下,为了防止端口冲突,需要自行管理端口,并且指定端口也必须在参数中声明的端口范围之内。
ExternalTrafficPolicy
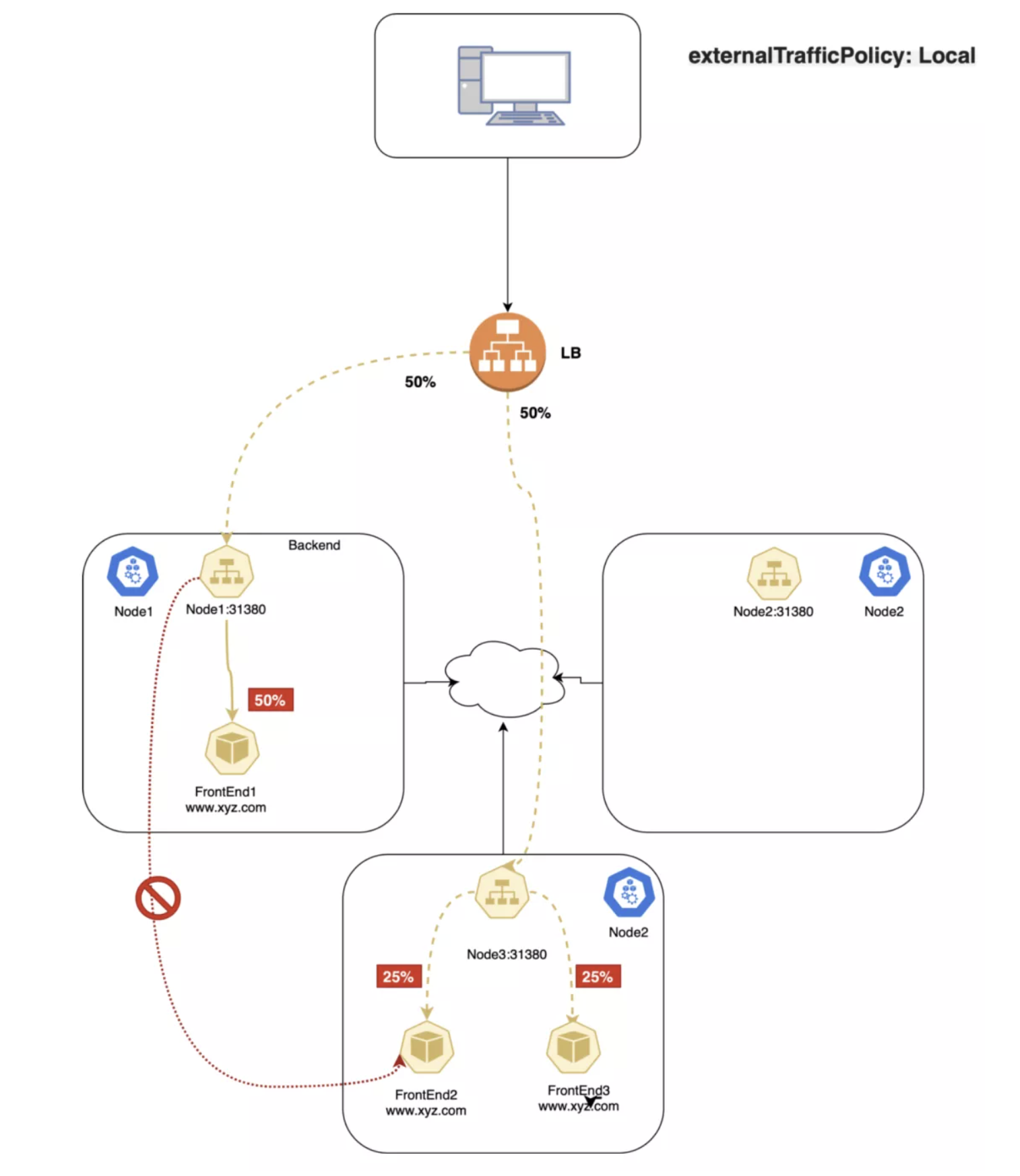
ExternalTrafficPolicy 字段表明所属 Service 对象会把来自外部的流量路由给本节点还是集群范围内的端点。如果赋值为 Local,会保留客户端源 IP 同时避免 NodePort 类型服务的多余一跳,但是有流量分配不均匀的隐患;如果设置为 Cluster,会抹掉客户端的源 IP,并导致到其它节点的一跳,但会获得相对较好的均衡效果。
Cluster
这是 Kubernetes Service 的缺省 ExternalTrafficPolicy。这个选项会把流量平均分配给该 Service 的所有 Pod 上。
这种策略的一个弱点是会存在不必要的节点间网络跳转。例如在一个节点的 NodePort 上接收到流量时,即使本节点上存在可用 Pod,流量还是可能会随机地把流量路由到另外一个节点上的 Pod,造成不必要的跳转。
在 Cluster 策略下,数据包的流向:
- 客户端把数据包发送给
node2:31380; node2替换源 IP 地址(SNAT)为自己的 IP 地址;node2将目标地址替换为 Pod IP;- 数据包被路由到
node1或者node3,然后到达 Pod; - Pod 的响应返回到
node2; - Pod 的响应返回到客户端。
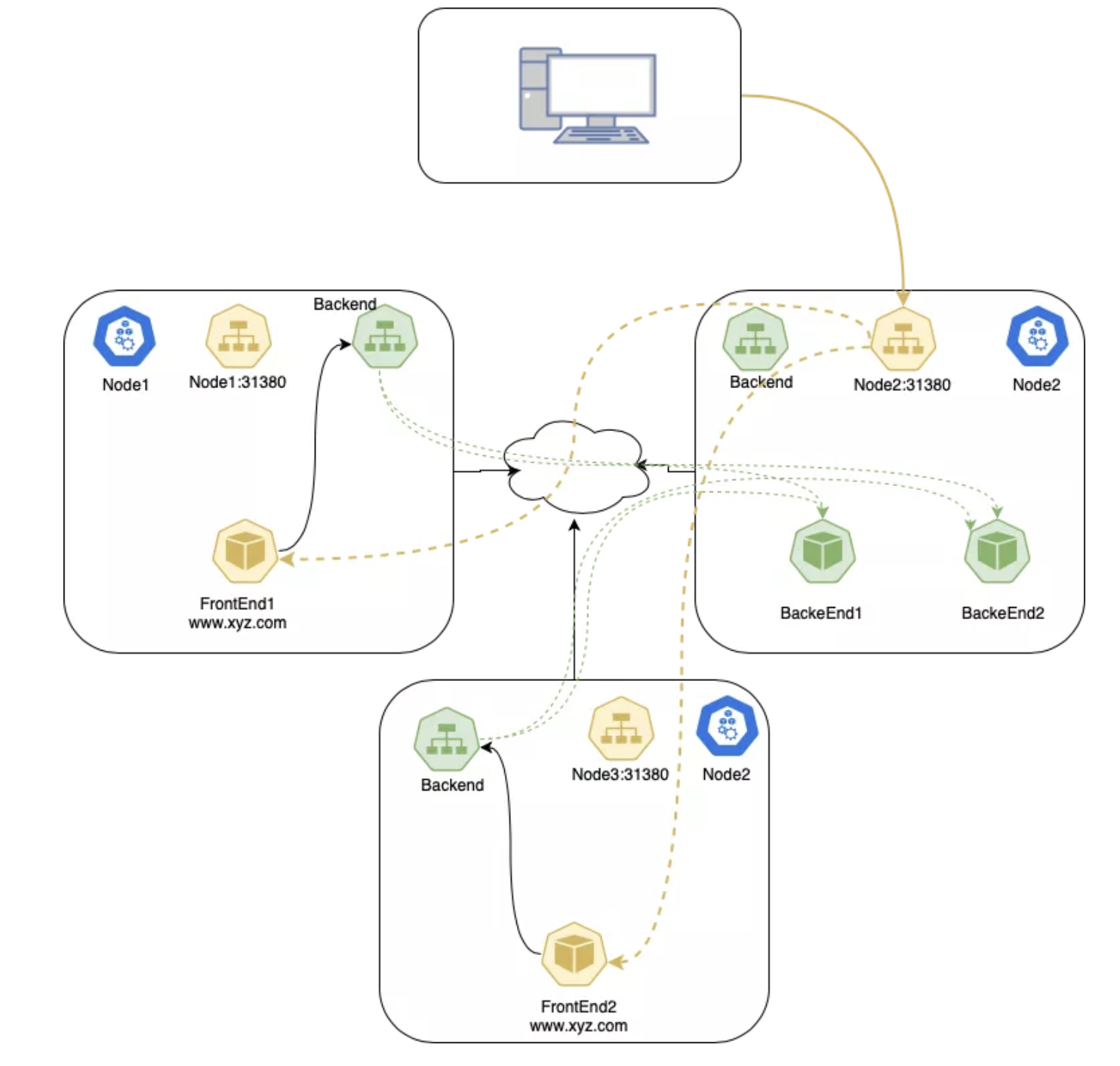
Local
这种策略中,kube-proxy 只会在存在目标 Pod 的节点上加入 NodePort 的代理规则。API Server 要求只有使用 LoadBalancer 或者 NodePort 类型的 Service 才能够使用这种策略。这是因为 Local 策略只跟外部访问相关。
如果使用了 Local 策略,kube-proxy 只会代理到本地 endpoint 的流量,不会向其它节点转发。如果本地没有相应端点,发送到该节点的流量就会被丢弃,所以数据包中会保留正确的源 IP,可以放心的在数据包处理规则中使用。
---
apiVersion: v1
kind: Service
metadata:
name: frontend
spec:
type: NodePort
externalTrafficPolicy: Local
selector:
app: webapp
ports:
# By default and for convenience, the `targetPort` is set to the same value as the `port` field.
- port: 80
targetPort: 80
# Optional field
# By default and for convenience, the Kubernetes control plane will allocate a port from a range (default: 30000-32767)
nodePort: 31380
...
Local 策略下的数据包:
- 客户端发送数据包到
node1:31380,这个端点上存在目标 Pod; node1把数据包路由到端点,其中带有正确的源 IP;- 因为策略限制,
node1不会把数据包发给node3; - 客户端发送数据包给
node2:31380,该节点上不存在目标 Pod; - 数据包被丢弃。
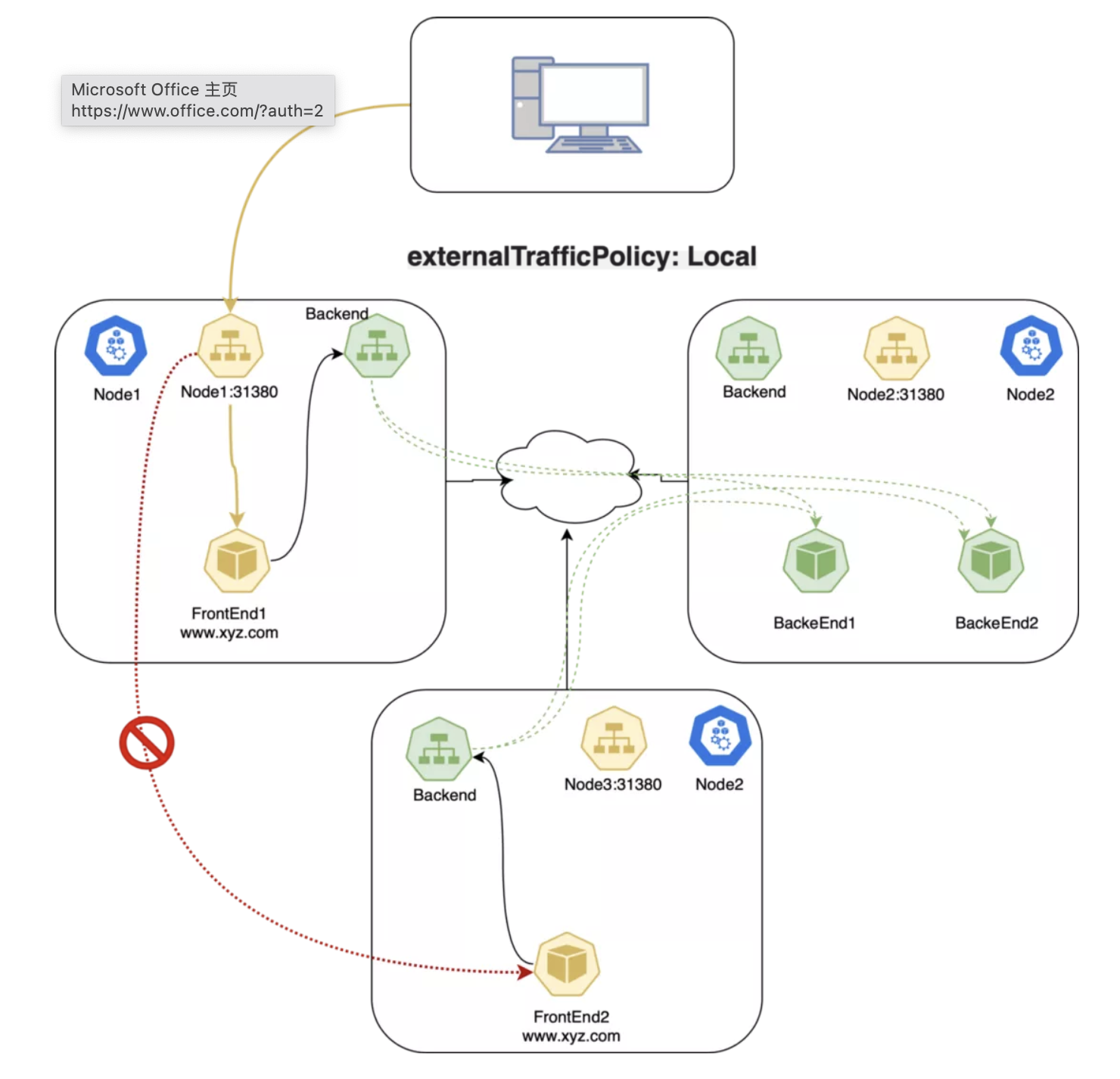
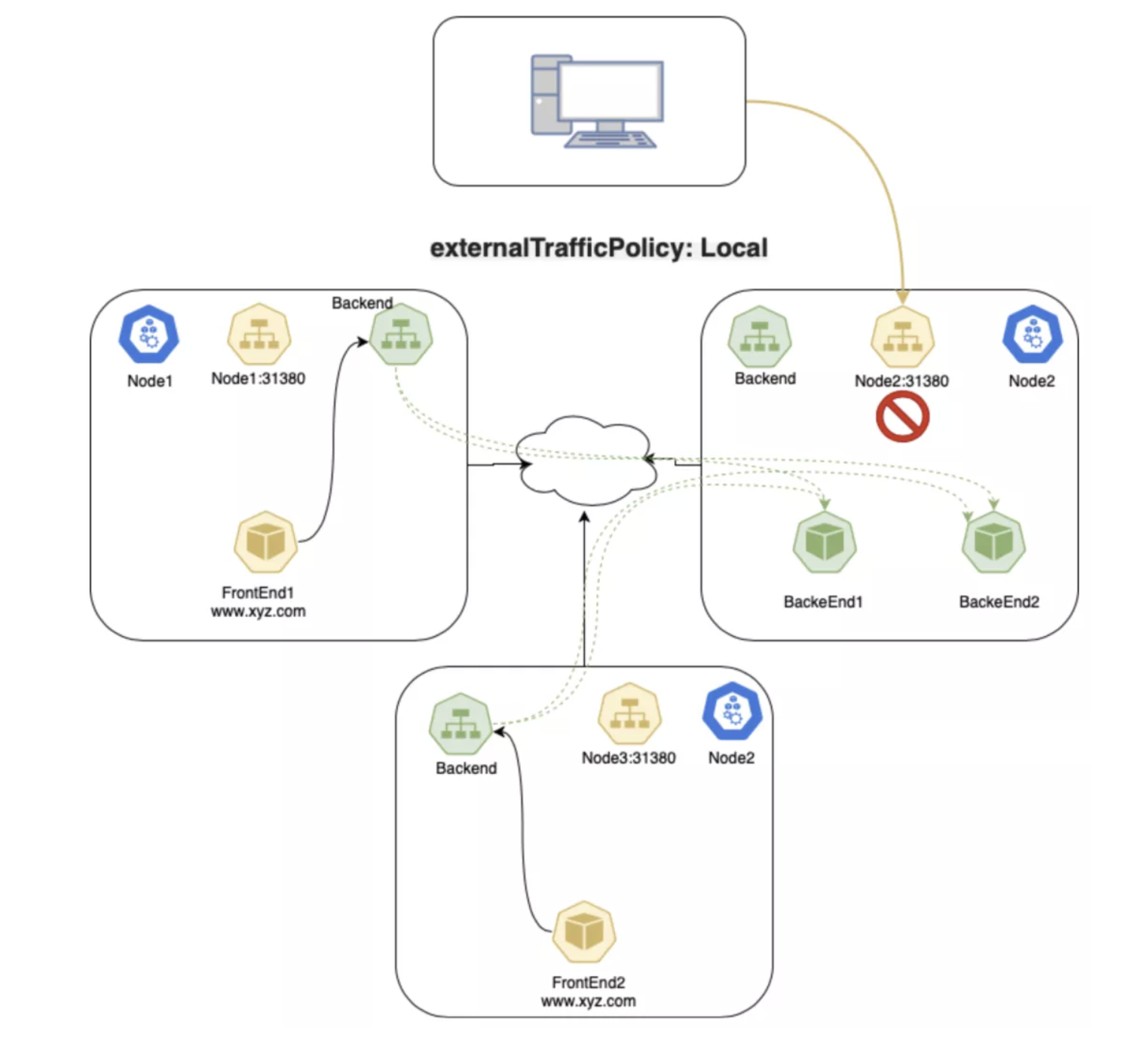
LoadBalancer Service 类型中的 Local 策略
如果在 Google GKE 上使用 Local 策略,由于健康检查的原因,会把不运行对应 Pod 的节点从负载均衡池中剔除,所以不会发生丢弃流量的问题。这种模型对于需要处理大量外部入栈流量,需要避免跨节点跳转从而降低延迟的应用非常有帮助。另外因为不需要进行 SNAT,从而让源 IP 得以保存。然而官方文档声明,这种策略存在不够均衡的短板。
Kube-Proxy(iptable)
Kubernetes 中负责 Service 对象的组件就是 kube-proxy。它在每个节点上运行,为 Pod 和 Service 生成复杂的 iptables 规则,完成所有的过滤和 NAT 工作。如果登录到 Kubernetes 节点上,运行 iptables-save,会看到 Kubernetes 或者其它组件生成的规则。最重要的是 KUBE-SERVICE、KUBE-SVC-* 以及 KUBE-SEP-*:
-
KUBE-SERVICE是Service包的入口。它负责匹配 IP:Port,并把数据包发给对应的
KUBE-SVC-*。 -
KUBE-SVC-*担任负载均衡的角色,会平均分配数据包到KUBE-SEP-*。每个
KUBE-SVC-*都有和Endpoint同样数量的KUBE-SEP-*。 -
KUBE-SEP-*代表的是Service的EndPoint,它负责的是 DNAT,会把Service的 IP:Port 替换为 Pod 的 IP:Port。
Conntrack 会介入 DNAT 过程,使用状态机来跟踪连接状态。为了记住目标地址的变更,并在回包时候进行恢复,这些状态是必须保存的。iptables 还可以根据 conntrack 状态(ctstate)来决定数据包的目标。下面四个 conntrack 状态尤其重要:
-
NEW:conntrack 对该数据包一无所知,该状态出现在收到
SYN的时候。 -
ESTABLISHED:conntrack 知道该数据包属于一个已发布连接,该状态出现于握手完成之后。
-
RELATED:这个数据包不属于任何连接,但是他是隶属于其它连接的,在 FTP 之类的协议里常用。
-
INVALID:有问题的数据包,conntrack 不知道如何处理。
这种状态是 Kubernetes 问题的常客。
Service 和 Pod 之间的 TCP 连接过程如下:
-
左侧的客户端 Pod 发送数据包到一个 Service:
2.2.2.10:80; -
数据包经过客户端节点的 iptables 规则,目标改为
1.1.1.20:80; -
服务端 Pod 处理数据包,发送一个响应包到
1.1.1.10; -
数据包回到客户端节点,conntrack 认出这个数据包,把源地址改回
2.2.2.10:80; -
客户端 Pod 收到响应包。
iptables
在 Linux 操作系统中使用 netfilter 处理防火墙工作。这是一个内核模块,决定是否放行数据包。iptables 是 netfilter 的前端。二者经常被混为一谈。
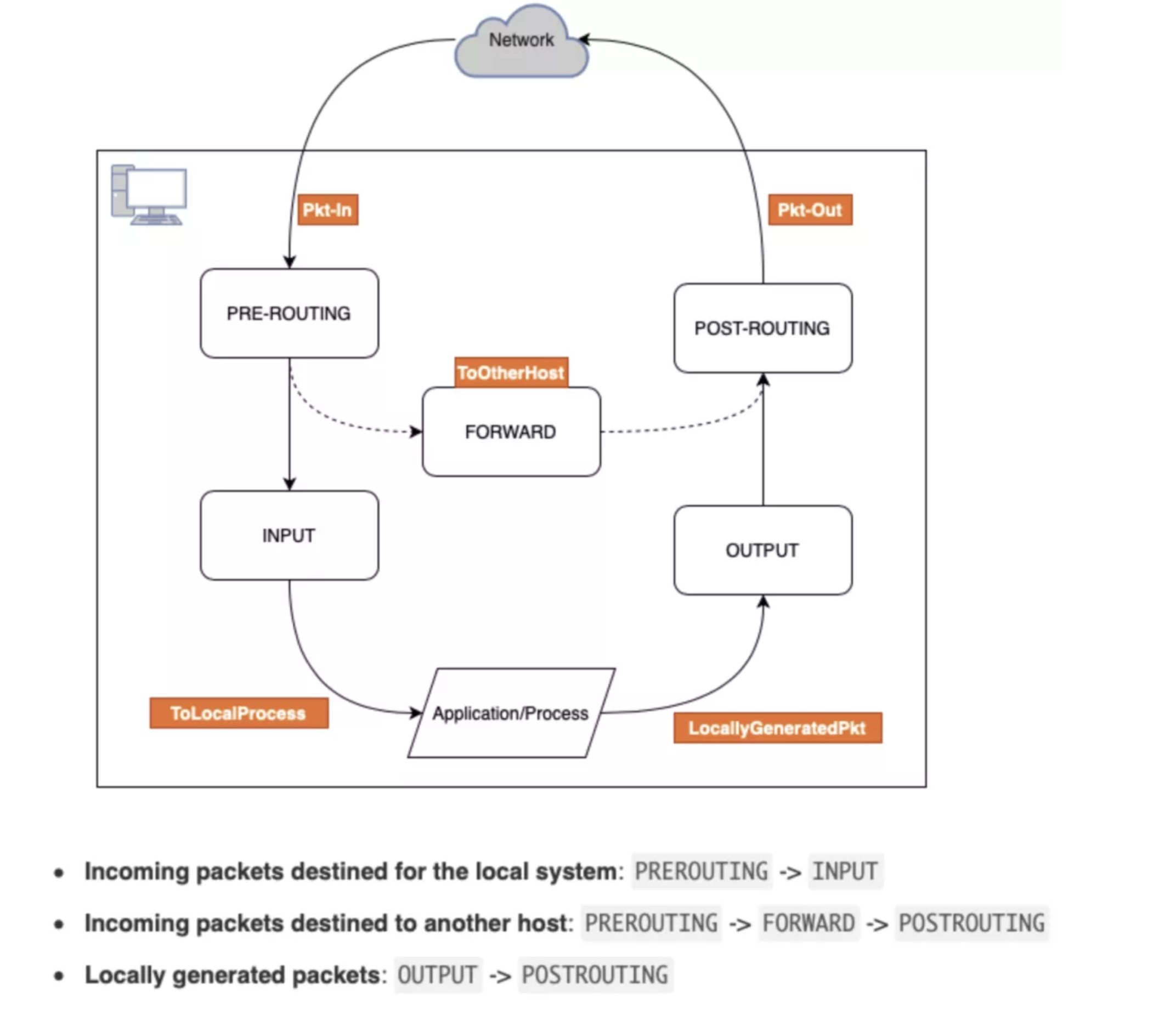
链
每条链负责一种特定任务。
-
PREROUTING:决定数据包刚刚进入网络端口时的对策。
有几种不同的选择,例如修改数据包(NAT),丢弃数据包或者什么都不做使其通过;
-
INPUT:其中经常包含一些用于防止恶意行为的严格规则,防止系统遭到入侵。
开放或者屏蔽端口的行为就是在这里进行的;
-
FORWARD:顾名思义,负责数据包的转发。
在将服务器作为路由器的时候,就需要在这里完成任务。
-
OUTPUT:这里负责所有的网络浏览的行为。
这里可以限制所有数据包的发送。
-
POSTROUTING:发生在数据包离开服务器之前,数据包最后的可跟踪位置。
FORWARD 仅在 ip_forward 启用时才有效。所以下面的命令在 Kubernetes 中很重要:
$ sysctl -w net.ipv4.ip_forward=1
net.ipv4.ip_forward = 1
$ cat /proc/sys/net/ipv4/ip_forward
1
上面的变更是暂时性的,要持久化这个变更,需要在 /etc/sysctl.conf 中写入 net.ipv4.ip_forward = 1。
表
接下来会讨论 NAT 表,除此之外还有几个:
-
Filter:缺省表,这里决定是否允许数据包出入本机,因此可以在这里进行屏蔽等操作;
-
Nat:是网络地址转换的缩写。
下面会有例子说明;
-
Mangle:仅对特定包有用。
它的功能是在包出入之前修改包中的内容;
-
RAW:用于处理原始数据包,主要用在跟踪连接状态,下面有一个放行 SSH 连接的例子。
-
Security:负责在 Filter 之后保障安全。
Kubernetes 中的 iptables 配置
部署一个 2 副本 Nginx 应用,导出 iptables 规则。
服务类型 NodePort
$ kubectl get svc webapp
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
webapp NodePort 10.103.46.104 <none> 80:31380/TCP 3d13h
$ kubectl get ep webapp
NAME ENDPOINTS AGE
webapp 10.244.120.102:80,10.244.120.103:80 3d13h
ClusterIP 是一个存在于 iptables 中的虚拟 IP,Kubernetes 会把这个地址存在 CoreDNS 中。
$ kubectl exec -i -t dnsutils -- nslookup webapp.default
Server: 10.96.0.10
Address: 10.96.0.10#53
Name: webapp.default.svc.cluster.local
Address: 10.103.46.104
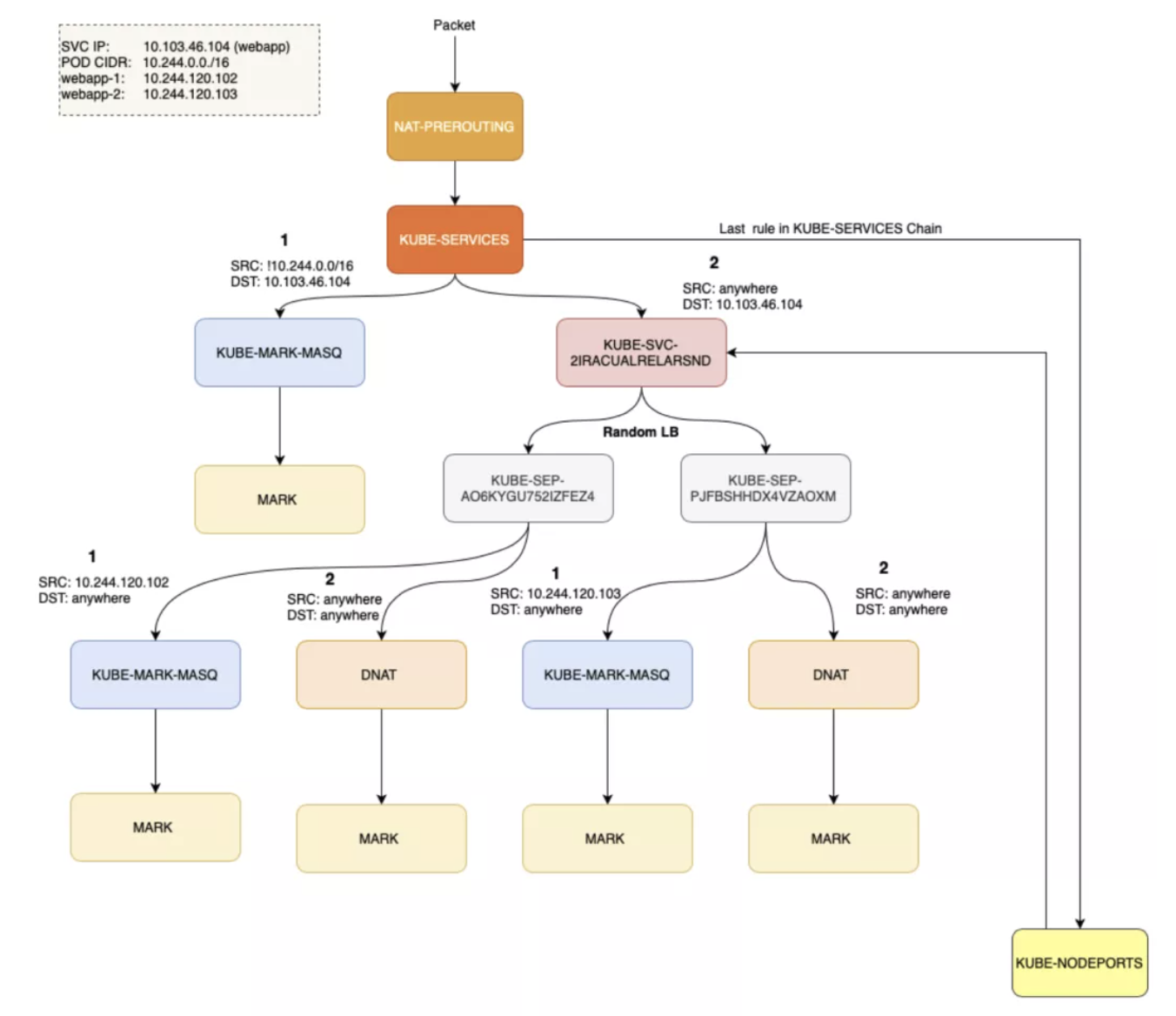
为了能够进行包过滤和 NAT,Kubernetes 会创建一个 KUBE-SERVICES 链,把所有 PREROUTING 和 OUTPUT 流量转发给 KUBE-SERVICES:
sudo iptables -t nat -L PREROUTING | column -t
Chain PREROUTING (policy ACCEPT)
target prot opt source destination
cali-PREROUTING all -- anywhere anywhere /* cali:6gwbT8clXdHdC1b1 */
KUBE-SERVICES all -- anywhere anywhere /* kubernetes service portals */
DOCKER all -- anywhere anywhere ADDRTYPE match dst-type LOCAL
使用 KUBE-SERVICES 介入包过滤和 NAT 之后,Kubernetes 会监控通向 Service 的流量,并进行 SNAT/DNAT 的处理。在 KUBE-SERVICES 链尾部,会写入另一个链 KUBE-SERVICES,用于处理 NodePort 类型的 Service。
KUBE-SVC-2IRACUALRELARSND 链会处理针对 ClusterIP 的流量,否则的话就会进入 KUBE-NODEPORTS:
$ sudo iptables -t nat -L KUBE-SERVICES | column -t
Chain KUBE-SERVICES (2 references)
target prot opt source destination
KUBE-MARK-MASQ tcp -- !10.244.0.0/16 10.103.46.104 /* default/webapp cluster IP */ tcp dpt:www
KUBE-SVC-2IRACUALRELARSND tcp -- anywhere 10.103.46.104 /* default/webapp cluster IP */ tcp dpt:www
KUBE-NODEPORTS all -- anywhere anywhere /* kubernetes service nodeports; NOTE: this must be the last rule in this chain */ ADDRTYPE match dst-type LOCAL
看看 KUBE-NODEPORTS 的内容:
$ sudo iptables -t nat -L KUBE-NODEPORTS | column -t
Chain KUBE-NODEPORTS (1 references)
target prot opt source destination
KUBE-MARK-MASQ tcp -- anywhere anywhere /* default/webapp */ tcp dpt:31380
KUBE-SVC-2IRACUALRELARSND tcp -- anywhere anywhere /* default/webapp */ tcp dpt:31380
看起来 ClusterIP 和 NodePort 处理过程是一样的,那么看看下面的处理流程:
# statistic mode random -> Random load-balancing between endpoints.
$ sudo iptables -t nat -L KUBE-SVC-2IRACUALRELARSND | column -t
Chain KUBE-SVC-2IRACUALRELARSND (2 references)
target prot opt source destination
KUBE-SEP-AO6KYGU752IZFEZ4 all -- anywhere anywhere /* default/webapp */ statistic mode random probability 0.50000000000
KUBE-SEP-PJFBSHHDX4VZAOXM all -- anywhere anywhere /* default/webapp */
$ sudo iptables -t nat -L KUBE-SEP-AO6KYGU752IZFEZ4 | column -t
Chain KUBE-SEP-AO6KYGU752IZFEZ4 (1 references)
target prot opt source destination
KUBE-MARK-MASQ all -- 10.244.120.102 anywhere /* default/webapp */
DNAT tcp -- anywhere anywhere /* default/webapp */ tcp to:10.244.120.102:80
$ sudo iptables -t nat -L KUBE-SEP-PJFBSHHDX4VZAOXM | column -t
Chain KUBE-SEP-PJFBSHHDX4VZAOXM (1 references)
target prot opt source destination
KUBE-MARK-MASQ all -- 10.244.120.103 anywhere /* default/webapp */
DNAT tcp -- anywhere anywhere /* default/webapp */ tcp to:10.244.120.103:80
$ sudo iptables -t nat -L KUBE-MARK-MASQ | column -t
Chain KUBE-MARK-MASQ (24 references)
target prot opt source destination
MARK all -- anywhere anywhere MARK or 0x4000
注意:输出内容已经被精简。
- ClusterIP:
KUBE-SERVICES→KUBE-SVC-XXX→KUBE-SEP-XXX - NodePort:
KUBE-SERVICES→KUBE-NODEPORTS→KUBE-SVC-XXX→KUBE-SEP-XXX
NodePort 服务会有一个 ClusterIP 用于处理内外部通信。
上述规则的可视化表达:
ExtrenalTrafficPolicy: Local
如前文所述,使用 ExtrenalTrafficPolicy: Local 会保留源 IP,并在到达节点上没有 Endpoint 的时候丢弃流量。没有本地 Endpoint 的节点上,iptables 的规则会怎样?
使用 ExtrenalTrafficPolicy: Local 部署 Nginx 服务:
$ kubectl get svc webapp -o wide -o jsonpath={.spec.externalTrafficPolicy}
Local
$ kubectl get svc webapp -o wide
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE SELECTOR
webapp NodePort 10.111.243.62 <none> 80:30080/TCP 29m app=webserver
检查一下没有本地 Endpoint 的节点上的 iptables 规则:
$ sudo iptables -t nat -L KUBE-NODEPORTS
Chain KUBE-NODEPORTS (1 references)
target prot opt source destination
KUBE-MARK-MASQ tcp — 127.0.0.0/8 anywhere /* default/webapp */ tcp dpt:30080
KUBE-XLB-2IRACUALRELARSND tcp — anywhere anywhere /* default/webapp */ tcp dpt:30080
再看一下 KUBE-XLB-2IRACUALRELARSND:
$ iptables -t nat -L KUBE-XLB-2IRACUALRELARSND
Chain KUBE-XLB-2IRACUALRELARSND (1 references)
target prot opt source destination
KUBE-SVC-2IRACUALRELARSND all — 10.244.0.0/16 anywhere /* Redirect pods trying to reach external loadbalancer VIP to clusterIP */
KUBE-MARK-MASQ all — anywhere anywhere /* masquerade LOCAL traffic for default/webapp LB IP */ ADDRTYPE match src-type LOCAL
KUBE-SVC-2IRACUALRELARSND all — anywhere anywhere /* route LOCAL traffic for default/webapp LB IP to service chain */ ADDRTYPE match src-type LOCAL
KUBE-MARK-DROP all — anywhere anywhere /* default/webapp has no local endpoints */
这里就会看到,集群级别的流量没什么问题,但是 NodePort 流量会被丢弃。
Headless Service
有的应用并不需要负载均衡和服务 IP。在这种情况下就可以使用 headless Service,只要设置 .spec.clusterIP 为 None 即可。
可以借助这种服务类型和其他服务发现机制协作,无需和 Kubernetes 绑定。kube-proxy 不对这种没有 IP 的服务提供支持,也就没有什么负载均衡和代理之类的能力了。DNS 的配置要根据 Selector 来确定。
有 Selector
定义了 Selector 的 Headless Service,Endpoint 控制器会创建 Endpoint 记录,并修改 DNS 记录来直接返回 Service 后端的 Pod 地址。
$ kubectl get svc webapp-hs
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
webapp-hs ClusterIP None <none> 80/TCP 24s
$ kubectl get ep webapp-hs
NAME ENDPOINTS AGE
webapp-hs 10.244.120.109:80,10.244.120.110:80 31s
无 Selector
没有定义 Selector 的 Headless Service,也就没有 Endpoint 记录。然而 DNS 系统会尝试配置:
ExternalName类型的服务,会产生CNAME记录;- 其他类型则是所有 Endpoint 共享服务名称。
如果外部 IP 被路由到集群节点上,Kubernetes Service 可以用 externalIPs 开放出来。通过 externalIP 进入集群的流量,会被路由到 Service Endpoint 上。externalIPs 不是 Kubernetes 管理的,需要集群管理员自行维护。
七、网络策略
阅读至此,Kubernetes 网络策略的实现方法已经呼之欲出了——是的,就是 iptables。目前是 CNI 而非 kube-proxy 负责实现网络策略。
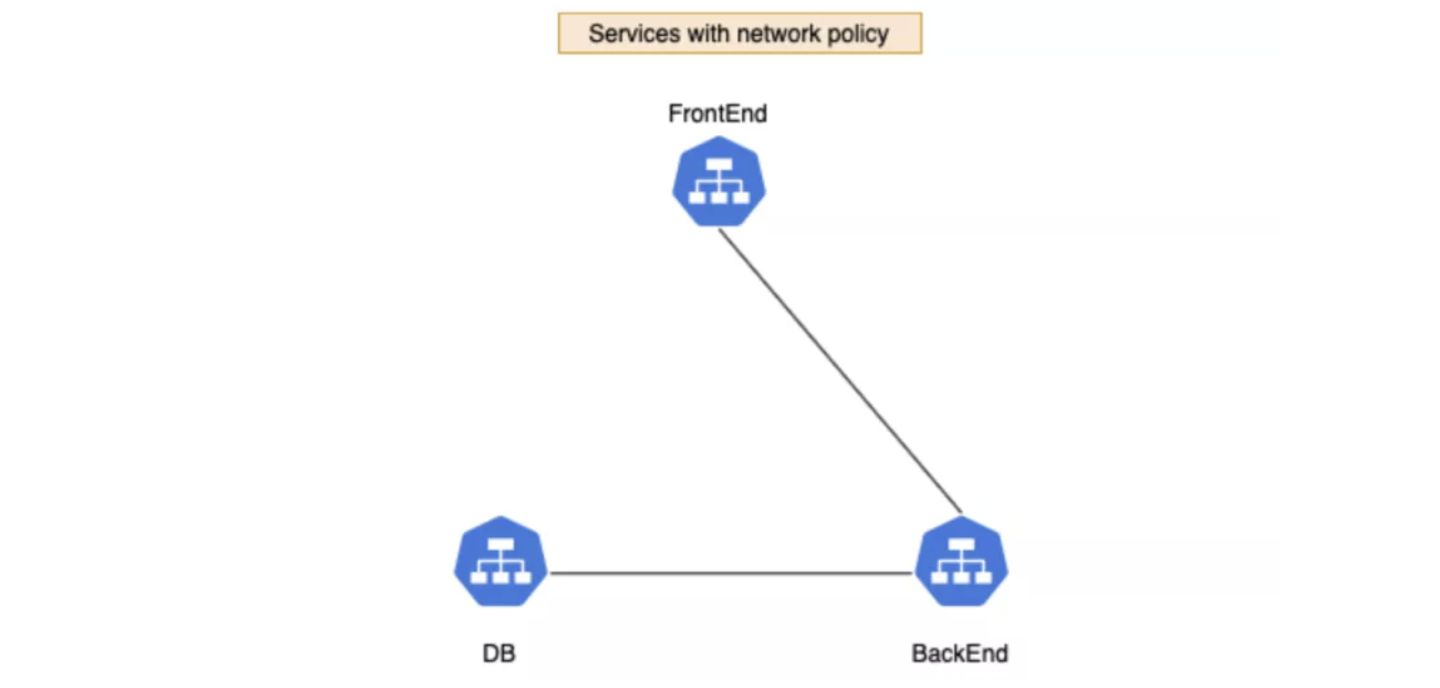
我们创建三个服务:frontend、backend 和 db。缺省情况下,Pod 没有任何隔离,会接受任何来源的通信。
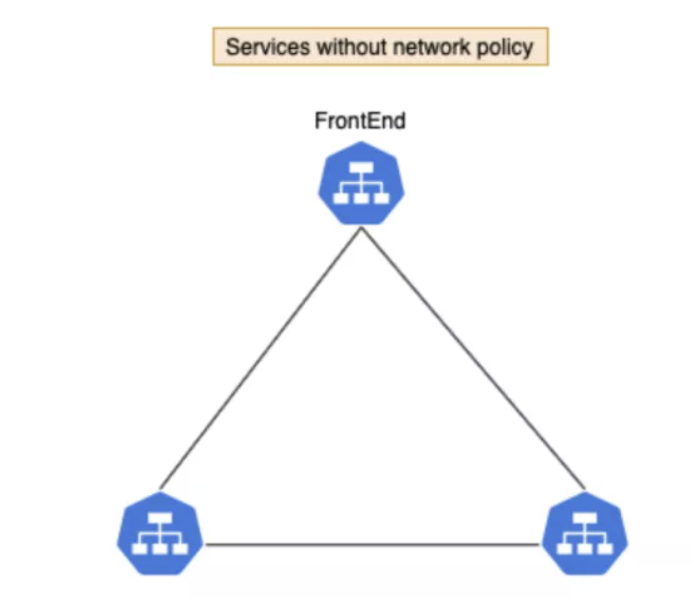
想要制定规则,禁止 frontend 访问 db:
这里推荐阅读 Guide to Kubernetes Ingress Network Policies 了解网络策略配置方面的更多内容。本节内容关注的是 Kubernetes 中策略的实现方式,而非配置知识。
创建一个策略把 db 和 frontend 隔离开,这样一来 frontend 和 db 之间的流量就会被阻断。
上图中为了简单起见,写的是 Service 而非 Pod,安全策略的控制对象实际上是 Pod。
策略实施之后会产生如下效果,frontend 的 Pod 能访问 backend 但是无法访问 db。backend 的 Pod 可以访问 db。
$ kubectl exec -it frontend-8b474f47-zdqdv -- /bin/sh
$ curl backend
backend-867fd6dff-mjf92
$ curl db
curl: (7) Failed to connect to db port 80: Connection timed out
$ kubectl exec -it backend-867fd6dff-mjf92 -- /bin/sh
$ curl db
db-8d66ff5f7-bp6kf
看看这里用到的网络策略:只允许 ‘allow-db-access 标签设置为 true 的 Pod 访问 db。
Calico 会把 Kubernetes 网络策略翻译成 Calico 格式:
$ calicoctl get networkPolicy --output yaml
apiVersion: projectcalico.org/v3
items:
- apiVersion: projectcalico.org/v3
kind: NetworkPolicy
metadata:
creationTimestamp: "2020-11-05T05:26:27Z"
name: knp.default.allow-db-access
namespace: default
resourceVersion: /53872
uid: 1b3eb093-b1a8-4429-a77d-a9a054a6ae90
spec:
ingress:
- action: Allow
destination: {}
source:
selector: projectcalico.org/orchestrator == 'k8s' && networking/allow-db-access
== 'true'
order: 1000
selector: projectcalico.org/orchestrator == 'k8s' && app == 'db'
types:
- Ingress
kind: NetworkPolicyList
metadata:
resourceVersion: 56821/56821
iptables 的 filter 表在网络策略的实现中起了很重要的作用。Calico 中用到了 ipsec 等高级概念,难于进行反向工程。在这个规则中可以看到,只有来自 backend 的流量才被允许发给 db。
使用 calicoctl 获取 endpoint 详情:
$ calicoctl get workloadEndpoint
WORKLOAD NODE NETWORKS INTERFACE
backend-867fd6dff-mjf92 minikube 10.88.0.27/32 cali2b1490aa46a
db-8d66ff5f7-bp6kf minikube 10.88.0.26/32 cali95aa86cbb2a
frontend-8b474f47-zdqdv minikube 10.88.0.24/32 cali505cfbeac50
cali95aa86cbb2a 就是 db Pod veth 的主机侧。
看看跟这个网络接口有关的 iptables 规则:
$ sudo iptables-save | grep cali95aa86cbb2a
:cali-fw-cali95aa86cbb2a - [0:0]
:cali-tw-cali95aa86cbb2a - [0:0]
...
-A cali-tw-cali95aa86cbb2a -m comment --comment "cali:pm-LK-c1ra31tRwz" -m mark --mark 0x0/0x20000 -j cali-pi-_tTE-E7yY40ogArNVgKt
-A cali-tw-cali95aa86cbb2a -m comment --comment "cali:q_zG8dAujKUIBe0Q" -m comment --comment "Return if policy accepted" -m mark --mark 0x10000/0x10000 -j RETURN
-A cali-tw-cali95aa86cbb2a -m comment --comment "cali:FUDVBYh1Yr6tVRgq" -m comment --comment "Drop if no policies passed packet" -m mark --mark 0x0/0x20000 -j DROP
-A cali-tw-cali95aa86cbb2a -m comment --comment "cali:X19Z-Pa0qidaNsMH" -j cali-pri-kns.default
-A cali-tw-cali95aa86cbb2a -m comment --comment "cali:Ljj0xNidsduxDGUb" -m comment --comment "Return if profile accepted" -m mark --mark 0x10000/0x10000 -j RETURN
-A cali-tw-cali95aa86cbb2a -m comment --comment "cali:0z9RRvvZI9Gud0Wv" -j cali-pri-ksa.default.default
-A cali-tw-cali95aa86cbb2a -m comment --comment "cali:pNCpK-SOYelSULC1" -m comment --comment "Return if profile accepted" -m mark --mark 0x10000/0x10000 -j RETURN
-A cali-tw-cali95aa86cbb2a -m comment --comment "cali:sMkvrxvxj13WlTMK" -m comment --comment "Drop if no profiles matched" -j DROP
$ sudo iptables-save -t filter | grep cali-pi-_tTE-E7yY40ogArNVgKt
:cali-pi-_tTE-E7yY40ogArNVgKt - [0:0]
-A cali-pi-_tTE-E7yY40ogArNVgKt -m comment --comment "cali:M4Und37HGrw6jUk8" -m set --match-set cali40s:LrVD8vMIGQDyv8Y7sPFB1Ge src -j MARK --set-xmark 0x10000/0x10000
-A cali-pi-_tTE-E7yY40ogArNVgKt -m comment --comment "cali:sEnlfZagUFRSPRoe" -m mark --mark 0x10000/0x10000 -j RETURN
检查一下 ipset,会看到只有来自 backend pod 的 10.88.0.27 才能访问 db。
最后我们会跟进 Kubernetes 的 Ingress 和 Ingress 控制器。Ingress 控制器会关注 API Server 中 Ingress 对象的更新,并据此配置 Ingress 的负载均衡。
Nginx控制器和负载均衡/代理服务器
Ingress控制器[5]一般是会以Pod形式运行在 Kubernetes 集群中的应用,它会根据集群中的 Ingress 对象的变化对负载均衡器进行配置。这里说的负载均衡器可以是一个集群内运行的软件,也可以是一个硬件,还可以是集群外部运行的云基础设施。不同的负载均衡器需要不同的Ingress控制器。
Ingress 的基本目标是提供一个相对高级的流量(尤其是 [http(s)])管理能力。使用Ingress可以在无需创建多个负载均衡或者对外开放多个 Service 的条件下,为服务流量进行路由。可以给服务配置外部 URL、进行负载均衡、终结 SSL 以及根据主机名或者内容进行路由等
配置选项
在把 Ingress 对象转换为负载均衡配置之前,Kubernetes Ingress控制器会用 Ingress Class 对 Kubernetes 的 Ingress 对象进行过滤。这样就允许多个 Ingress 控制器共存,各司其职。
基于前缀
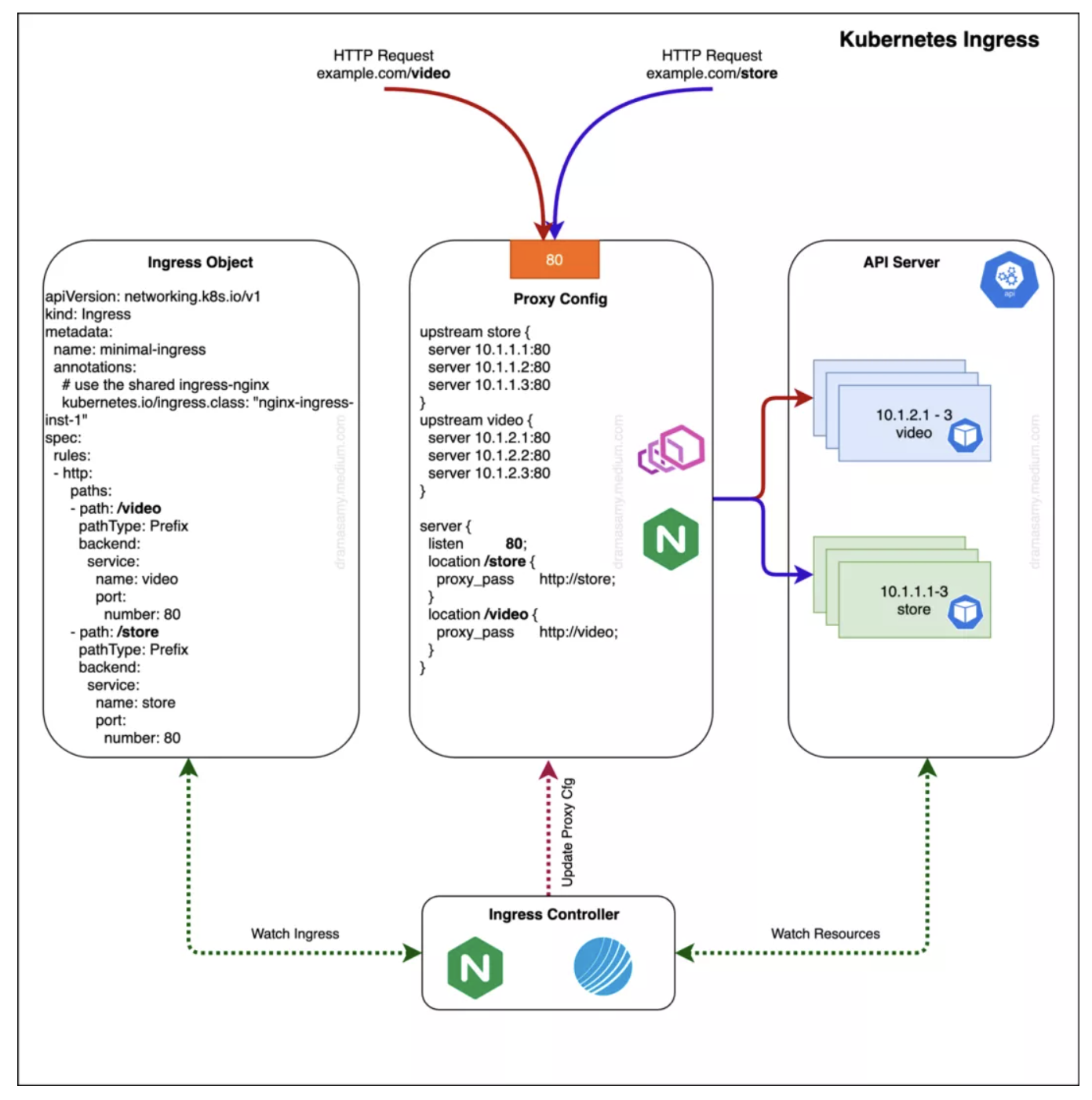
apiVersion: networking.k8s.io/v1
kind: Ingress
metadata:
name: prefix-based
annotations:
kubernetes.io/ingress.class: "nginx-ingress-inst-1"
spec:
rules:
- http:
paths:
- path: /video
pathType: Prefix
backend:
service:
name: video
port:
number: 80
- path: /store
pathType: Prefix
backend:
service:
name: store
port:
number: 80
基于主机
apiVersion: networking.k8s.io/v1
kind: Ingress
metadata:
name: host-based
annotations:
kubernetes.io/ingress.class: "nginx-ingress-inst-1"
spec:
rules:
- host: "video.example.com"
http:
paths:
- pathType: Prefix
path: "/"
backend:
service:
name: video
port:
number: 80
- host: "store.example.com"
http:
paths:
- pathType: Prefix
path: "/"
backend:
service:
name: store
port:
number: 80
主机加前缀
apiVersion: extensions/v1beta1
kind: Ingress
metadata:
name: host-prefix-based
annotations:
kubernetes.io/ingress.class: "nginx-ingress-inst-1"
spec:
rules:
- host: foo.com
http:
paths:
- backend:
serviceName: foovideo
servicePort: 80
path: /video
- backend:
serviceName: foostore
servicePort: 80
path: /store
- host: bar.com
http:
paths:
- backend:
serviceName: barvideo
servicePort: 80
path: /video
- backend:
serviceName: barstore
servicePort: 80
path: /store
Ingress 是一个内置 API 对象,但是 Kubernetes 并没有内置任何 Ingress 控制器,需要另行安装控制器才能真正地使用 Ingress。Ingress 功能是由 API 对象和控制器协同完成的。Ingress 对象负责描述集群中 Service 对象的开放需求。而控制器则负责真正的实现 Ingress API,根据 Ingress 对象的定义内容来完成实际工作。市面上有很多不同的 Ingress 控制器,需要根据实际用例谨慎地进行选择使用。
同一集群里可以有多个 Ingress 控制器,并为每个 Ingress 直接指派具体的控制器,在同一个集群中可以根据不同需要为不同服务配置不同的 Ingress。例如某服务用于一个 Ingress 处理来自集群外的 SSL 流量,另外一个用于处理集群内的明文通信。
部署选项
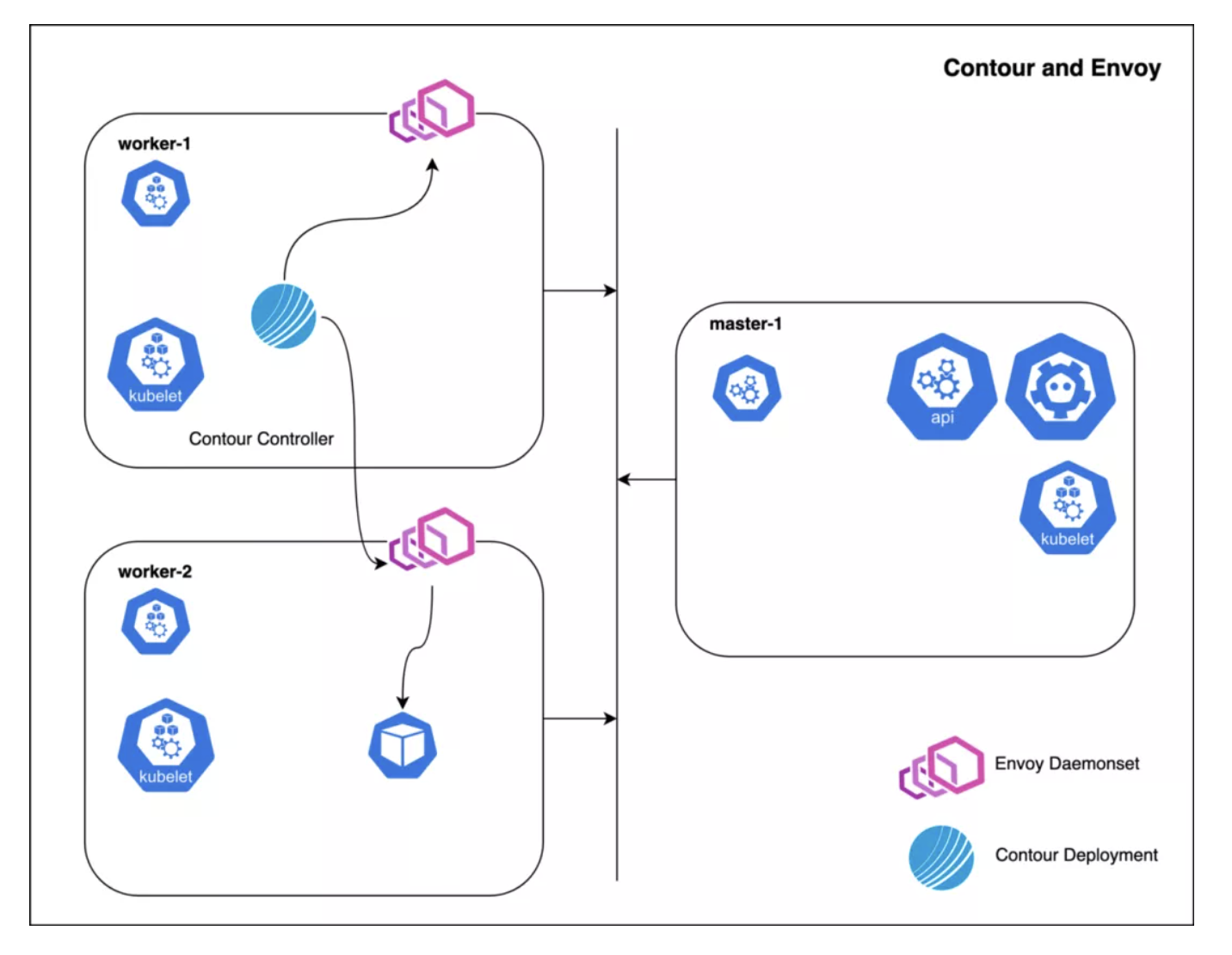
Contour[6] + Envoy[7]
Contour Ingress 控制器由两部分组成:
- Envoy 提供了高性能的反向代理服务;
- Contour 负责对 Envoy 进行管理,为其下发配置。
这些容器是各自部署的,Contour 是一个 Deployment,而 Envoy 则是一个 Daemonset,当然也可以用其他模式进行部署。Contour 是 Kubernetes API 的客户端,会跟踪 Ingress、HTTPProxy、Secret、Service 以及 Endpoint 对象,并承担管理 Envoy 的职责,它会把它的对象缓存转换为 Envoy 的 JSON 报文,Service 转换为 CDS、Ingress 转为 RDS、Endpoint 转换为 EDS 等。
下面的例子展示了启用 Host Network 的 EnvoyProxy:
Nginx
Nginx Ingress 控制器[8]的主要能力之一就是生成配置文件(nginx.conf)。这个实现还有个需要就是在配置发生变化之后重载 Nginx。在只有 upstream 发生变化时(例如部署调整时产生的 Endpoint 变化)不会进行重载,而是通过 lua-nginx-module[9] 完成任务。
每次 Endpoint 发生变动,控制器会从所有服务中拉取 Endpoint,生成对应的后端对象。这些对象会被发送给 Nginx 中运行的 Lua 处理器。Lua 代码会把这些对象保存到共享内存区域。每次 balancer_by_lua 都会检查一下 upstream 中的有效节点,以此为目标按照预配置的算法进行负载均衡。如果在一个较大的集群中有比较频繁的发布行为,这种避免重载的方式能够大幅减少重载次数,从而更好地保障了响应的延迟时间,达成较高的负载均衡水平。
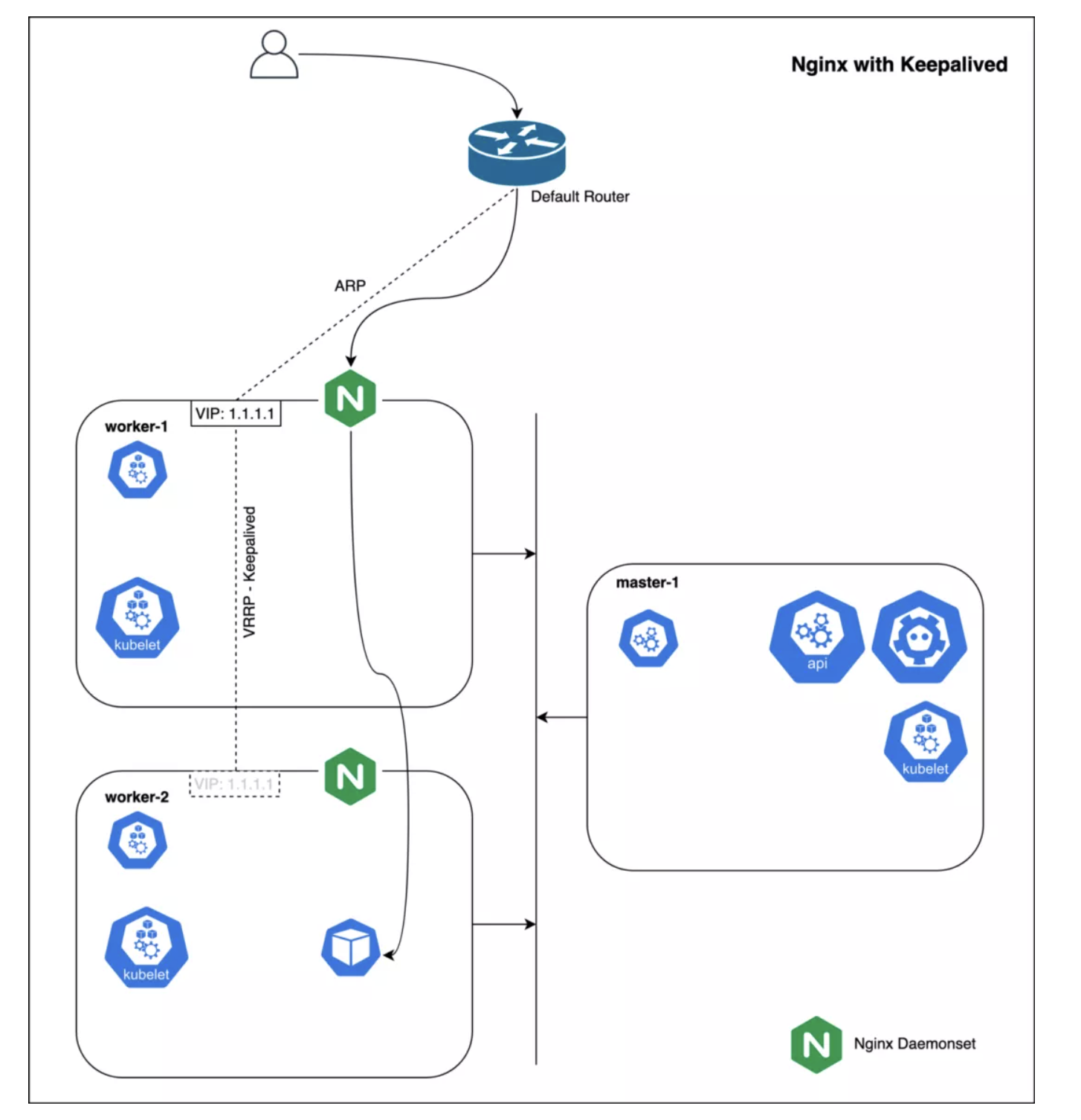
Nginx+ Keepalived[10] —— 高可用部署
Keepalived 守护进程可以监控服务或者系统,如果发现问题,能够进行自动的切换。配置一个能在节点之间转移的浮动 IP。如果节点宕机,浮动 IP 会自动漂移到其它节点,Nginx 可以绑定到新的 IP 地址。
MetalLB[11] — 面向具备少量公有 IP 池的私有集群的负载均衡服务
部署到 Kubernetes 中的 MetalLB 为集群提供了一个负载均衡的实现。简单说来,MetalLB 能够在非公有云 Kubernetes 环境中对 LoadBalancer 类型的 Service 提供支持。在托管 Kubernetes 环境中,申请一个负载均衡之后,云平台会给这个新的负载均衡分配 IP;MetalLB 可以负责这个分配过程。MetalLB 给 Service 分配外部 IP 之后,需要声明该 IP 属于本集群,它使用标准路由协议来完成这一任务:ARP、NDP 或 BGP。
在 2 层模式中,集群的一个节点获取这个 Service 的所有权,然后使用标准的地址发现协议(IPv4 使用 ARP、IPv6 使用 NDP)在本地网中让次 IP 可达。从局域网的角度来看,这个节点只是多了一个 IP 地址。
在 BGP 模式中,集群中的所有节点都会对附近的路由器发起 BGP 对等会话,告知路由器如何将流量转发给这些服务。BGP 的策略机制有细粒度的流量控制能力,能真正地在多个节点之间进行负载均衡。
MetalLB 的 Pod:
- Controller(Deployment)是集群级的 MetalLB 控制器,负责 IP 分配。
- Speaker(Daemonset)在每个节点上运行,使用多种发布策略公告服务和外部 IP 的对应关系。
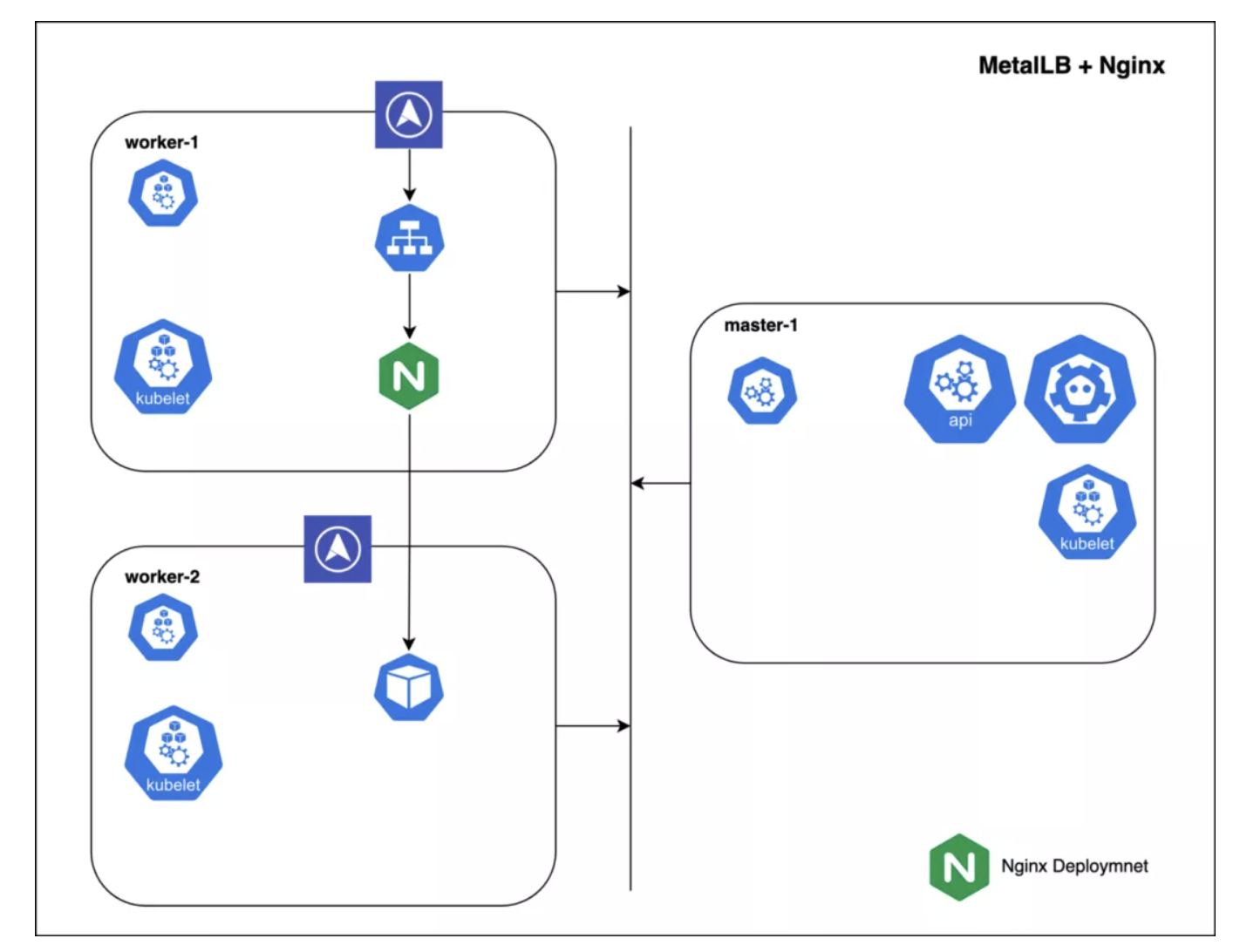
MetalLB 能够用在集群里的任何
LoadBalancer类型的 Service 中,但是 MetalLB 为大型 IP 地址池工作就不太现实了。
评论区